Testarea normalității în R este crucială înainte de a rula analize statistice parametrice precum testele t, ANOVA sau regresia liniară. Testul Shapiro-Wilk, graficul QQ (quantile-quantile plot) și histogramele sunt cele mai comune metode pentru verificarea asumpției de normalitate a datelor. Aceste teste presupun că datele tale urmează o distribuție normală (Gaussiană), iar violarea acestei asumpții poate duce la concluzii invalide în analiza statistică.
În acest ghid, vom acoperi metodele vizuale (histograme, grafice QQ), testele statistice (Shapiro-Wilk, Kolmogorov-Smirnov, Anderson-Darling) și cum să interpretezi rezultatele testelor de normalitate în R.
Ce Este Normalitatea?
Normalitatea se referă la faptul dacă datele urmează o distribuție normală. O distribuție normală, numită și distribuție Gaussiană, este o curbă în formă de clopot caracterizată de media și deviația standard. Media reprezintă centrul distribuției, în timp ce deviația standard reprezintă răspândirea datelor în jurul mediei.
Distribuția normală este importantă deoarece multe teste statistice parametrice (teste t, ANOVA, regresie liniară) presupun că datele analizate urmează o distribuție normală. Dacă datele tale violează această asumpție de normalitate, aceste teste statistice pot produce rezultate inexacte sau concluzii invalide.
Metode Vizuale pentru Verificarea Normalității în R
Metodele vizuale oferă o modalitate intuitivă de a evalua dacă datele tale urmează o distribuție normală. Iată cele două abordări vizuale cele mai comune:
1. Histograma
O histogramă este o reprezentare grafică care arată distribuția de frecvență a datelor tale. Dacă datele urmează o distribuție normală, histograma va afișa o curbă simetrică, în formă de clopot.
Iată cum să creezi o histogramă în R:
# Creează date exemplu
data <- rnorm(100)
# Creează histograma
hist(data, main = "Histograma Datelor Exemplu",
xlab = "Valoare", col = "lightblue")Acest cod generează 100 de numere aleatorii dintr-o distribuție normală standard (media = 0, deviația standard = 1) folosind funcția rnorm() și creează o histogramă folosind funcția hist().
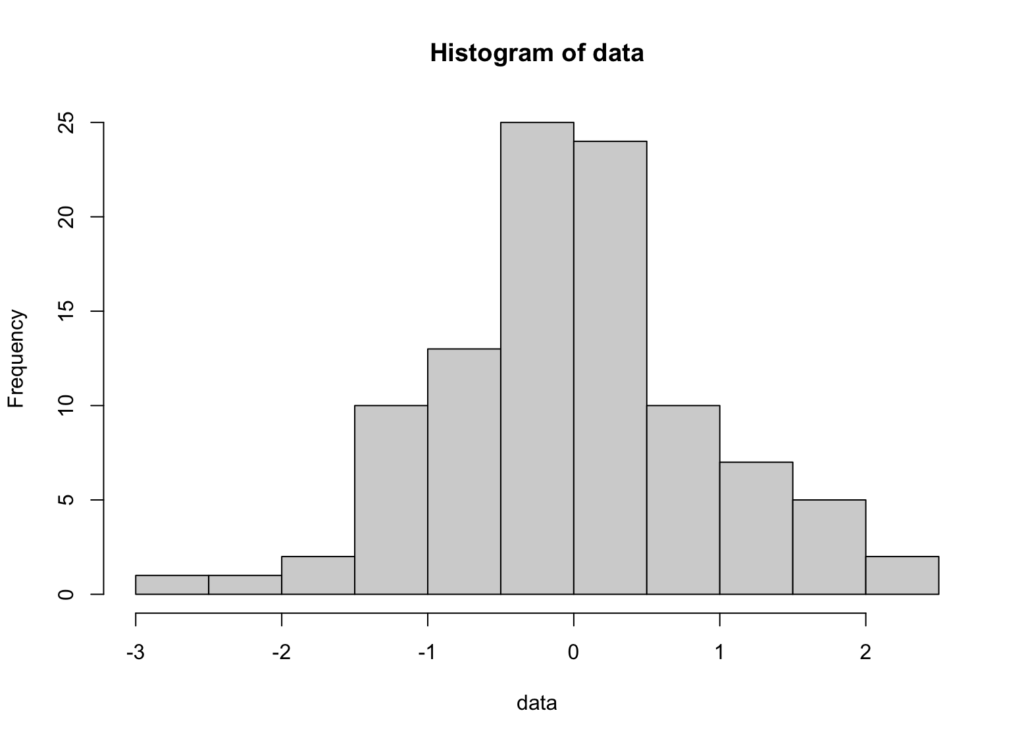
Interpretare: Dacă histograma arată o curbă simetrică, în formă de clopot, centrată în jurul mediei, datele tale probabil urmează o distribuție normală. Distribuțiile asimetrice sau multimodale indică abateri de la normalitate.
2. Grafic QQ (Quantile-Quantile Plot)
Un grafic QQ (quantile-quantile plot) compară cuantilele datelor tale cu cuantilele unei distribuții normale teoretice. Este una dintre cele mai fiabile metode vizuale pentru evaluarea normalității.
Iată cum să creezi un grafic QQ în R:
# Creează date exemplu
data <- rnorm(100)
# Creează grafic QQ
qqnorm(data, main = "Grafic Q-Q Normal")
qqline(data, col = "red")Acest cod generează 100 de numere aleatorii dintr-o distribuție normală standard și creează un grafic QQ folosind funcția qqnorm(). Funcția qqline() adaugă o linie de referință reprezentând o distribuție normală perfectă.
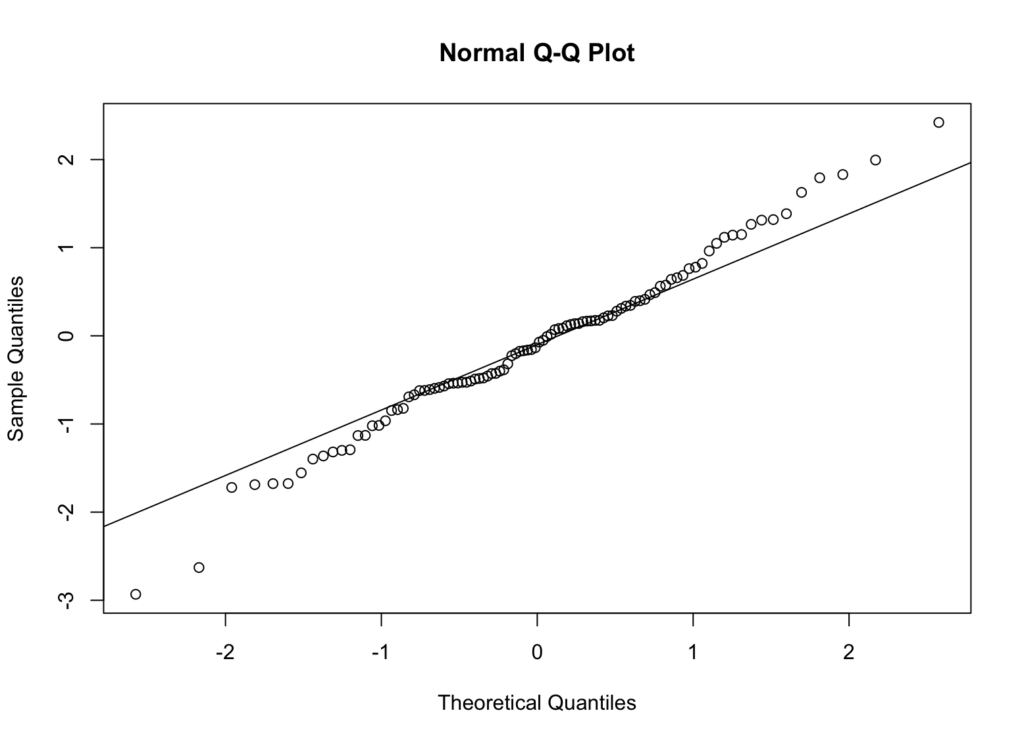
Interpretare: Dacă datele tale urmează o distribuție normală, punctele ar trebui să cadă aproximativ de-a lungul liniei de referință. Abaterile sistematice de la linie indică non-normalitate:
- Puncte curbate deasupra liniei la capete sugerează cozi grele
- Puncte curbate sub linie la capete sugerează cozi ușoare
- Tiparele în formă de S indică asimetrie
Teste Statistice pentru Normalitate în R
Deși metodele vizuale sunt utile, testele statistice oferă evaluări obiective, cantitative ale normalității. Iată cele mai comune teste de normalitate în R:
1. Testul Shapiro-Wilk
Testul Shapiro-Wilk este unul dintre cele mai puternice teste de normalitate, în special pentru dimensiuni mici și medii ale eșantionului (n < 2000).
Ipoteze:
- Ipoteza nulă (H₀): Datele urmează o distribuție normală
- Ipoteza alternativă (H₁): Datele nu urmează o distribuție normală
Iată cum să efectuezi testul Shapiro-Wilk în R:
# Creează date exemplu
data <- rnorm(100)
# Efectuează testul Shapiro-Wilk
shapiro.test(data)Acest cod generează 100 de numere aleatorii dintr-o distribuție normală standard și efectuează un test Shapiro-Wilk folosind funcția shapiro.test().

Interpretare:
- valoarea p > 0.05: Nu respingem ipoteza nulă; datele par distribuite normal
- valoarea p ≤ 0.05: Respingem ipoteza nulă; datele deviază semnificativ de la normalitate
Notă: Testul Shapiro-Wilk poate fi excesiv de sensibil cu dimensiuni mari ale eșantionului, detectând abateri triviale de la normalitate care au impact practic redus.
2. Testul Kolmogorov-Smirnov
Testul Kolmogorov-Smirnov (K-S) compară funcția de distribuție cumulativă a datelor tale cu o distribuție normală teoretică.
# Creează date exemplu
data <- rnorm(100)
# Efectuează testul Kolmogorov-Smirnov
ks.test(data, "pnorm", mean = mean(data), sd = sd(data))Interpretare: Similar cu testul Shapiro-Wilk, o valoare p > 0.05 sugerează că datele urmează o distribuție normală.
Notă: Testul K-S este mai puțin puternic decât testul Shapiro-Wilk pentru detectarea abaterilor de la normalitate, în special în cozile distribuției.
3. Testul Anderson-Darling
Testul Anderson-Darling pune mai multă greutate pe cozile distribuției decât testul Kolmogorov-Smirnov, făcându-l mai sensibil la abateri în cozi.
# Instalează și încarcă pachetul dacă este necesar
# install.packages("nortest")
library(nortest)
# Creează date exemplu
data <- rnorm(100)
# Efectuează testul Anderson-Darling
ad.test(data)Interpretare: O valoare p > 0.05 indică că datele sunt consistente cu o distribuție normală.
Alegerea Testului de Normalitate Potrivit
Teste diferite de normalitate au puncte forte diferite și sunt potrivite pentru situații diferite:
Testul Shapiro-Wilk:
- Cel mai bun pentru dimensiuni mici și medii ale eșantionului (n < 2000)
- Cel mai puternic test de normalitate
- Poate fi excesiv de sensibil cu eșantioane mari
Testul Kolmogorov-Smirnov:
- Potrivit pentru orice dimensiune a eșantionului
- Test cu scop general
- Mai puțin puternic decât Shapiro-Wilk
Testul Anderson-Darling:
- Bun pentru detectarea abaterilor în cozile distribuției
- Funcționează cu orice dimensiune a eșantionului
- Necesită pachetul nortest
Recomandare: Pentru majoritatea aplicațiilor cu dimensiuni ale eșantionului sub 2,000, folosește testul Shapiro-Wilk combinat cu grafice QQ pentru confirmare vizuală.
Întrebări Frecvente
Concluzie
Testarea normalității în R este o abilitate fundamentală pentru analiștii de date și statisticieni. Acest ghid a acoperit atât metodele vizuale (histograme și grafice QQ), cât și testele statistice (Shapiro-Wilk, Kolmogorov-Smirnov și Anderson-Darling) pentru a evalua dacă datele tale urmează o distribuție normală.
Amintește-ți să folosești o combinație de abordări: începe cu inspecția vizuală folosind histograme și grafice QQ, apoi confirmă cu teste statistice precum testul Shapiro-Wilk. Înțelegerea normalității este esențială înainte de a efectua analize statistice parametrice, deoarece violările asumpției de normalitate pot duce la concluzii incorecte.
Pentru majoritatea aplicațiilor cu dimensiuni ale eșantionului sub 2,000, testul Shapiro-Wilk combinat cu vizualizarea graficului QQ oferă cea mai fiabilă evaluare a normalității în R.