คุณพร้อมที่จะยกระดับทักษะการวิเคราะห์ข้อมูลของคุณด้วย Descriptive Statistics ใน R หรือยัง? ถ้าพร้อมแล้ว มาเริ่มกันเลย!
Descriptive Statistics คือชุดของเทคนิคที่ช่วยเราสรุปและอธิบายลักษณะหลักของชุดข้อมูล ช่วยให้เราเข้าใจข้อมูลได้อย่างรวดเร็วและง่ายดาย และมักเป็นขั้นตอนแรกในกระบวนการวิเคราะห์ข้อมูลใดๆ
ในบทเรียนนี้ เราจะดำดิ่งสู่โลกของ Descriptive Statistics ใน R เราจะเริ่มต้นด้วยการเตรียมชุดข้อมูลยอดขาย จากนั้นคำนวณค่าสถิติเชิงพรรณนาที่สำคัญ เช่น Mean, Median และ Mode, Range, Standard Deviation และ Variance และเมื่อเรามีค่าสถิติเหล่านี้แล้ว เราจะใช้มันเพื่อเข้าใจข้อมูลของเราได้ดีขึ้นและเริ่มตัดสินใจอย่างมีข้อมูลรองรับ
แต่ยังไม่หมดเพียงเท่านี้! เราจะมาดูการสร้างกราฟพื้นฐานใน R เช่น Histogram, Box Plot, Scatter Plot และ Trend Line การแสดงผลด้วยภาพเหล่านี้จะช่วยให้เราเข้าใจการกระจายตัวและความสัมพันธ์ภายในข้อมูลของเราได้ดีขึ้น
ดังนั้น คุณพร้อมที่จะเรียนรู้วิธีการทำ Descriptive Statistics ใน R แล้วหรือยัง? มาเริ่มกันเลย!
ขั้นตอนที่ 1: เตรียมชุดข้อมูลของคุณ
ขั้นตอนแรกคือการเตรียมชุดข้อมูลของคุณและจัดเก็บใน R เป็น Vector ในตัวอย่างนี้ เราจะใช้ข้อมูลยอดขาย 12 ตัวเลข แต่ละตัวแทนปริมาณยอดขายสำหรับเดือนมกราคมถึงธันวาคม:
sales <- c(16, 18, 13, 13, 14, 16, 21, 20, 19, 17, 15, 13)ขั้นตอนที่ 2: คำนวณค่าเฉลี่ย (Mean)
จุดแรกของเราคือค่าเฉลี่ย ซึ่งให้ข้อมูลเกี่ยวกับค่ายอดขายเฉลี่ยสำหรับทั้งปี เพื่อคำนวณค่าเฉลี่ยใน R เราใช้ฟังก์ชัน mean():
mean(sales)ผลลัพธ์จากการคำนวณค่าเฉลี่ยคือ 16.25 ซึ่งบอกเราว่ายอดขายเฉลี่ยสำหรับทั้งปีคือ 16.25 หน่วย
ขั้นตอนที่ 3: คำนวณค่ามัธยฐาน (Median)
ต่อไป เรามาคำนวณค่ามัธยฐานกัน Median คือค่ากลางในชุดข้อมูล และอาจเป็นตัวบ่งชี้ที่ดีกว่าของยอดขายทั่วไปหากข้อมูลเบ้ เพื่อคำนวณค่ามัธยฐานใน R เราใช้ฟังก์ชัน median():
median(sales)ผลลัพธ์จากการคำนวณค่ามัธยฐานคือ 16 ซึ่งบอกเราว่าค่ากลางของยอดขายสำหรับทั้งปีคือ 16 หน่วย
ขั้นตอนที่ 4: คำนวณฐานนิยม (Mode)
ค่าสถิติเชิงพรรณนาที่สำคัญอีกตัวหนึ่งคือฐานนิยม ซึ่งเป็นค่าที่ปรากฏบ่อยที่สุดในชุดข้อมูล เพื่อคำนวณฐานนิยมใน R เราใช้ฟังก์ชัน table() และ which.max():
mode <- table(sales)
mode[which.max(mode)]ผลลัพธ์จากการคำนวณฐานนิยมคือ 13 ซึ่งบอกเราว่ายอดขายที่พบบ่อยที่สุดสำหรับทั้งปีคือ 13 หน่วย
ขั้นตอนที่ 5: คำนวณช่วง (Range)
เรายังสามารถคำนวณช่วงได้ ซึ่งให้ข้อมูลเกี่ยวกับการกระจายของข้อมูล เพื่อคำนวณช่วงใน R เราใช้ฟังก์ชัน range():
range(sales)ผลลัพธ์จากการคำนวณช่วงคือ 8 ซึ่งบอกเราว่ายอดขายแตกต่างกัน 8 หน่วยระหว่างยอดขายต่ำสุด (13) และสูงสุด (21) สำหรับทั้งปี
ขั้นตอนที่ 6: คำนวณส่วนเบี่ยงเบนมาตรฐาน (Standard Deviation)
ต่อไป เรามาคำนวณส่วนเบี่ยงเบนมาตรฐานกัน Standard Deviation เป็นการวัดว่าข้อมูลกระจายตัวมากน้อยเพียงใด และให้ข้อมูลเกี่ยวกับว่ายอดขายแตกต่างจากค่าเฉลี่ยมากน้อยแค่ไหน
เพื่อคำนวณส่วนเบี่ยงเบนมาตรฐานใน R เราใช้ฟังก์ชัน sd():
sd(sales)ผลลัพธ์จากการคำนวณส่วนเบี่ยงเบนมาตรฐานคือ 2.8 ซึ่งบอกเราว่ายอดขายแตกต่างจากค่าเฉลี่ยโดยเฉลี่ย 2.8 หน่วย
ขั้นตอนที่ 7: คำนวณความแปรปรวน (Variance)
สุดท้าย เราจะคำนวณความแปรปรวน Variance คล้ายกับ Standard Deviation แต่แทนที่จะให้ค่าเบี่ยงเบนเฉลี่ยจากค่าเฉลี่ยเป็นหน่วย มันให้ค่าเบี่ยงเบนเฉลี่ยจากค่าเฉลี่ยยกกำลังสอง เพื่อคำนวณความแปรปรวนใน R เราใช้ฟังก์ชัน var():
var(sales)ผลลัพธ์จากการคำนวณความแปรปรวนคือ 7.84 ซึ่งบอกเราว่ายอดขายแตกต่างจากค่าเฉลี่ยโดยเฉลี่ย 7.84 หน่วยยกกำลังสอง
ขั้นตอนที่ 8: สร้าง Histogram
ตอนนี้เราได้คำนวณค่าสถิติเชิงพรรณนาพื้นฐานแล้ว มาดูข้อมูลในรูปแบบภาพโดยการสร้าง Histogram กัน เพื่อสร้าง Histogram ใน R เราใช้ฟังก์ชัน hist():
hist(sales)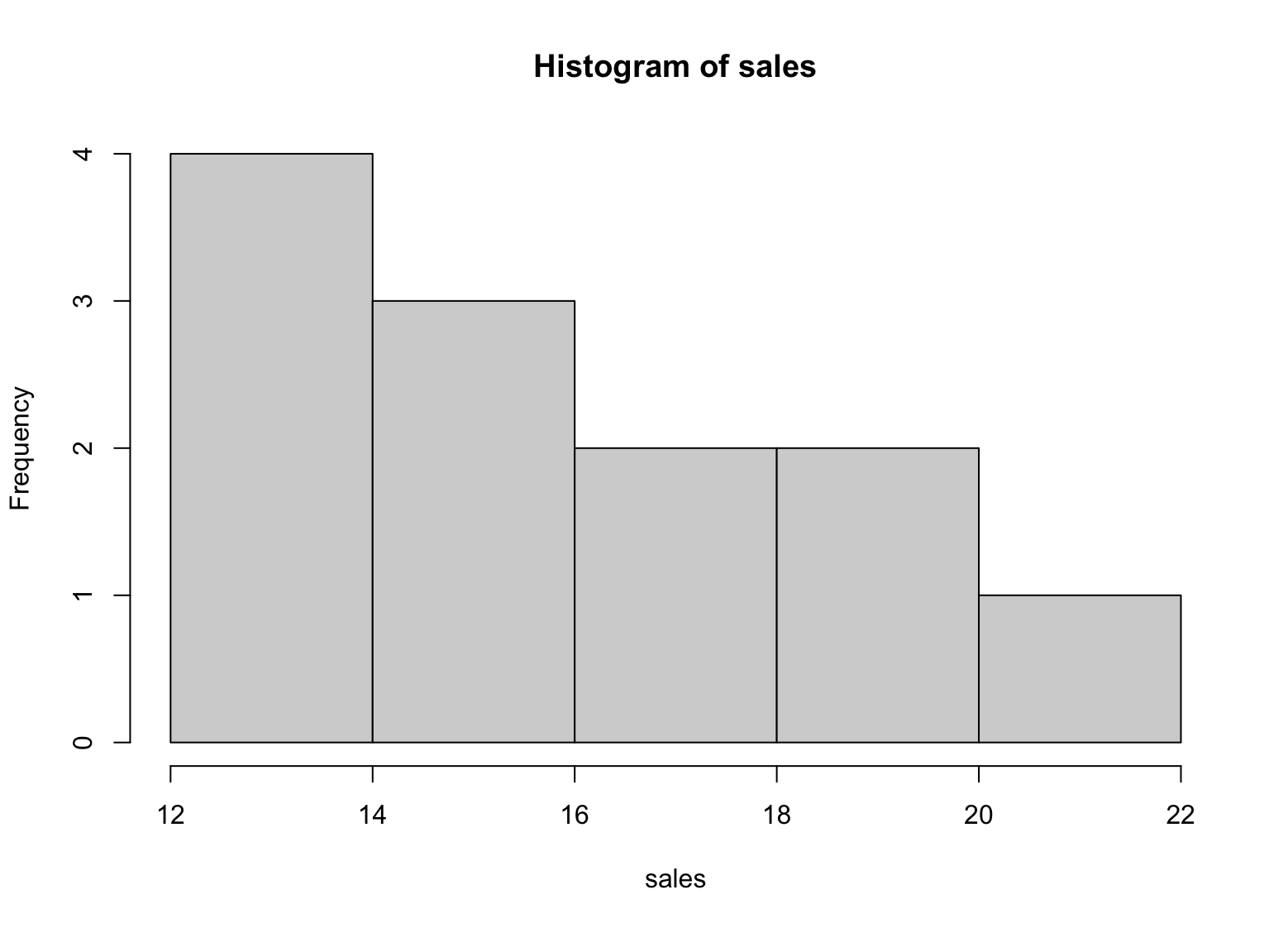
ตัวอย่าง Histogram สำหรับ Descriptive Statistics ใน R
Histogram ให้การแสดงภาพของการกระจายของยอดขายสำหรับทั้งปี มันแสดงให้เราเห็นว่ายอดขายส่วนใหญ่อยู่ระหว่าง 13 และ 18 และมียอดขายน้อยลงที่ด้านสูงและต่ำของช่วง
ขั้นตอนที่ 9: เพิ่ม Scatter Plot
เพื่อสร้าง Scatter Plot ใน R คุณสามารถใช้ฟังก์ชัน plot() ไวยากรณ์พื้นฐานมีดังนี้:
plot(x, y, main = "Scatter Plot", xlab = "X Variable", ylab = "Y Variable", pch = 16)ที่นี่ x และ y คือตัวแปรที่คุณต้องการพล็อต Argument main คือชื่อของกราฟ xlab และ ylab คือป้ายกำกับสำหรับแกน x และ y ตามลำดับ และ pch คือสัญลักษณ์การพล็อตที่ใช้
เนื่องจากเรามีตัวแปรเดียวในข้อมูลยอดขายของเรา เราสามารถพล็อตมันกับลำดับของหมายเลขยอดขายของเราเพื่อสร้าง Scatter Plot:
x <- 1:12
plot(x, sales, main = "Scatter Plot of Sales", xlab = "Month", ylab = "Sales", pch = 16)สิ่งนี้จะสร้าง Scatter Plot ของข้อมูลยอดขาย โดยมีเดือนบนแกน x และยอดขายบนแกน y Argument pch ตั้งค่าสัญลักษณ์การพล็อตเป็นวงกลมทึบ (16)
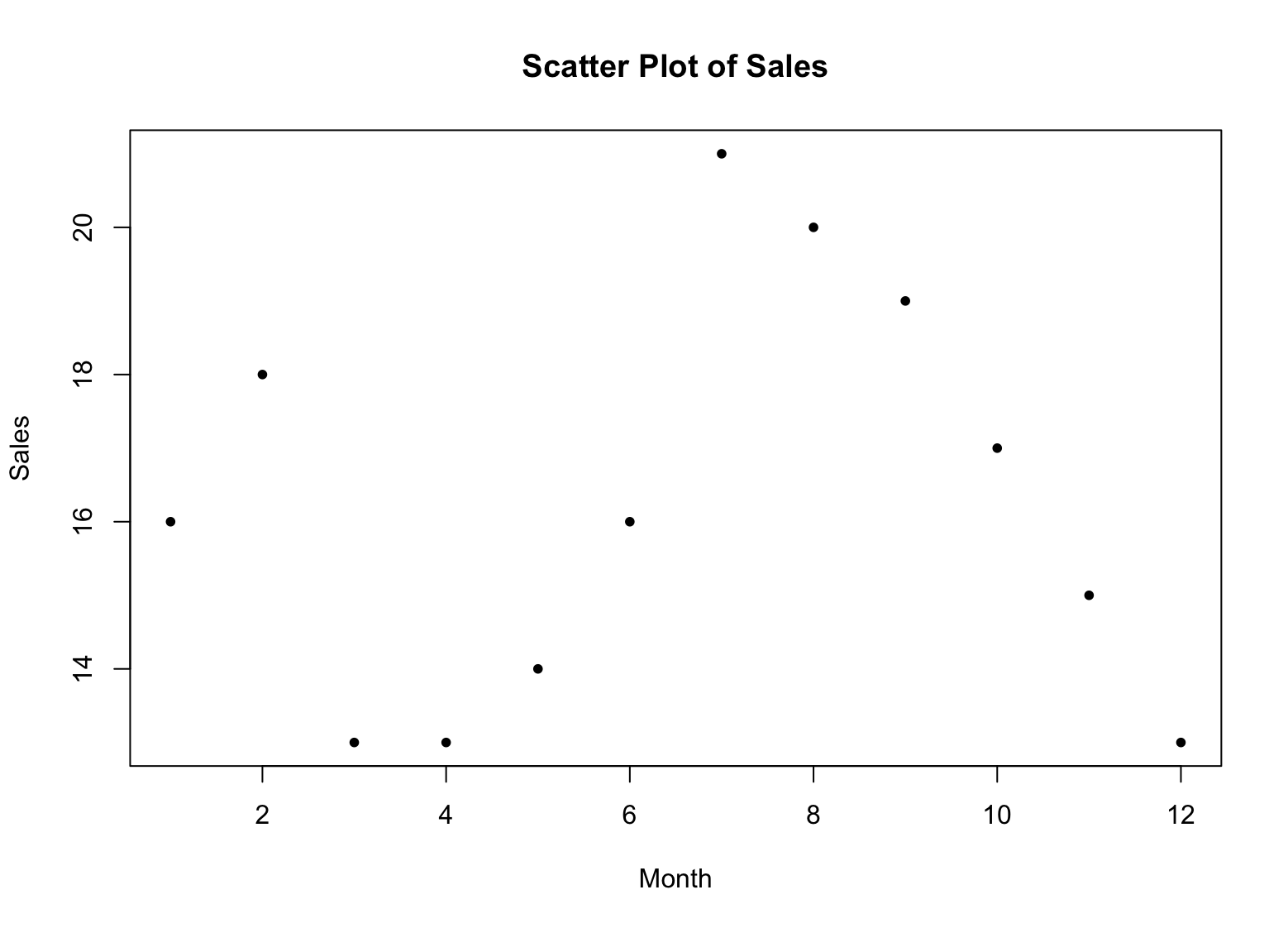
ตัวอย่าง Scatter Plot ใน R
อืม.. เราได้จุดหลายจุด แต่ผมคิดว่าจะง่ายต่อการมองเห็นมากขึ้นถ้าเรามีเส้นเชื่อมจุดเหล่านี้ นี่คือไวยากรณ์เพื่อเชื่อมจุดด้วยเส้นสีน้ำเงิน:
lines(x, sales, type = "l", col = "blue")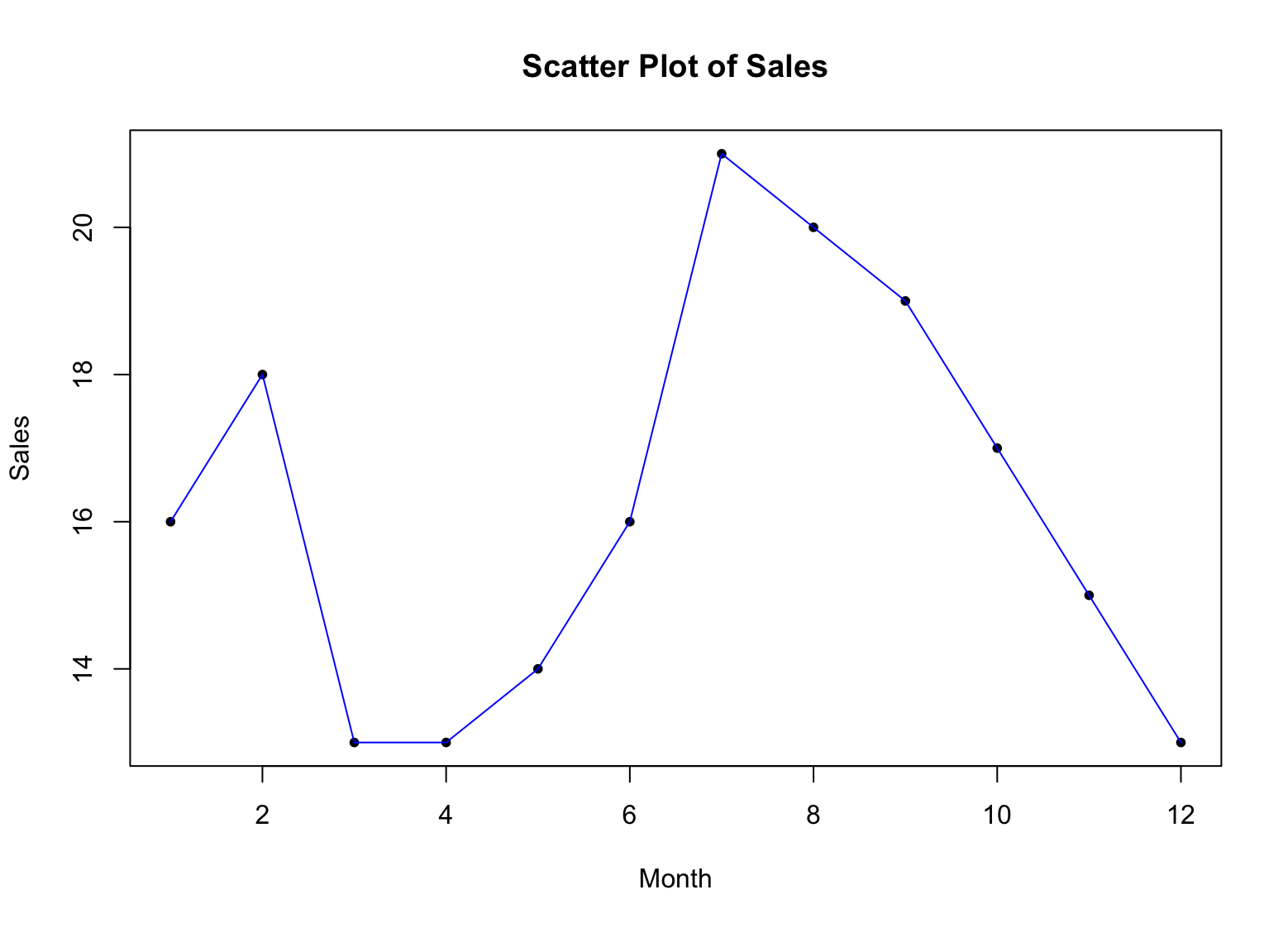
ตัวอย่าง Scatter Plot พร้อมเส้นเชื่อมใน R
เอาล่ะ แล้วต่อไป? เราจะเข้าใจกราฟนี้ในบริบทของข้อมูลยอดขายของเราได้อย่างไร?
-
แต่ละจุดบน Scatter Plot แทนข้อมูลเดียว โดยแกน x แทนเดือนและแกน y แทนยอดขาย
-
โดยการดูการกระจายตัวของจุดบน Scatter Plot คุณสามารถเข้าใจว่ายอดขายกระจายตัวอย่างไรในแต่ละเดือน หากจุดรวมกันแน่น แสดงว่ายอดขายคล้ายกันในแต่ละเดือน หากจุดกระจายมากขึ้น แสดงว่ายอดขายมีความแปรปรวนมากขึ้นในแต่ละเดือน
-
โดยการมองหารูปแบบในการกระจายของจุด คุณสามารถระบุแนวโน้มหรือรูปแบบในข้อมูล ตัวอย่างเช่น หากจุดเป็นเส้นตรง แสดงว่ามีความสัมพันธ์เชิงเส้นระหว่างเดือนและยอดขาย หากจุดเป็นเส้นโค้ง แสดงว่ามีความสัมพันธ์แบบไม่เชิงเส้นระหว่างเดือนและยอดขาย
-
Outliers แสดงเป็นจุดแต่ละจุดที่แตกต่างอย่างมีนัยสำคัญจากข้อมูลที่เหลือ โดยการระบุ Outliers คุณสามารถดูได้ว่ามีเดือนใดที่มียอดขายสูงหรือต่ำอย่างมีนัยสำคัญ ซึ่งอาจต้องมีการสืบสวนเพิ่มเติม
มาทำให้ Scatter Plot ของเรามีความหมายมากขึ้นและเพิ่ม Trend Line โดยใช้ฟังก์ชัน abline():
fit <- lm(sales ~ x)
abline(fit, col = "red")สิ่งนี้จะเพิ่ม Regression Line ลงในกราฟ แสดงแนวโน้มโดยรวมในข้อมูลยอดขาย Argument col ตั้งค่าสีของเส้นเป็นสีแดง แน่นอนคุณสามารถเลือกสีอื่นใดที่คุณชอบได้
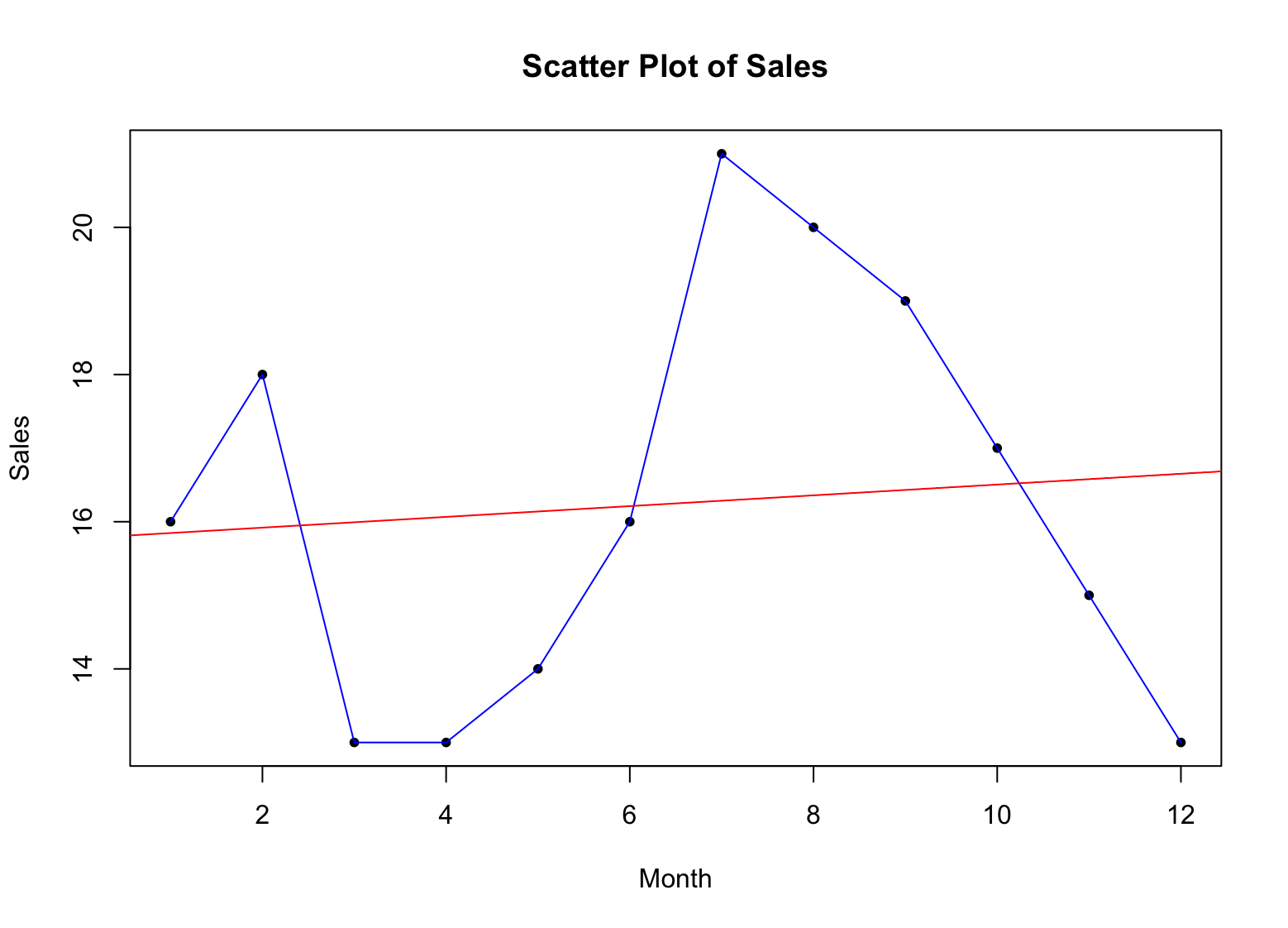
ตัวอย่าง Scatter Plot พร้อม Trend Line สำหรับ Descriptive Statistics ใน R
ขั้นตอนที่ 10: สร้าง Box and Whisker Plot
ใน R คุณสามารถสร้าง Box and Whisker Plot หรือที่เรียกว่า Boxplot โดยใช้ฟังก์ชัน boxplot() ไวยากรณ์พื้นฐานมีดังนี้:
boxplot(x, main = "Box and Whisker Plot", xlab = "Group", ylab = "Value", col = "blue")ที่นี่ x คือตัวแปรที่คุณต้องการพล็อต main คือชื่อของกราฟ xlab และ ylab คือป้ายกำกับสำหรับแกน x และ y ตามลำดับ และ col คือสีของ Boxplot
ตัวอย่างเช่น เพื่อสร้าง Box and Whisker Plot ของข้อมูลยอดขาย คุณสามารถใช้โค้ดดังนี้:
boxplot(sales, main = "Box and Whisker Plot of Sales", xlab = "Month", ylab = "Sales", col = "blue")สิ่งนี้จะสร้าง Box and Whisker Plot ของข้อมูลยอดขาย โดยมีเดือนบนแกน x และยอดขายบนแกน y Argument col ตั้งค่าสีของ Boxplot เป็นสีน้ำเงิน
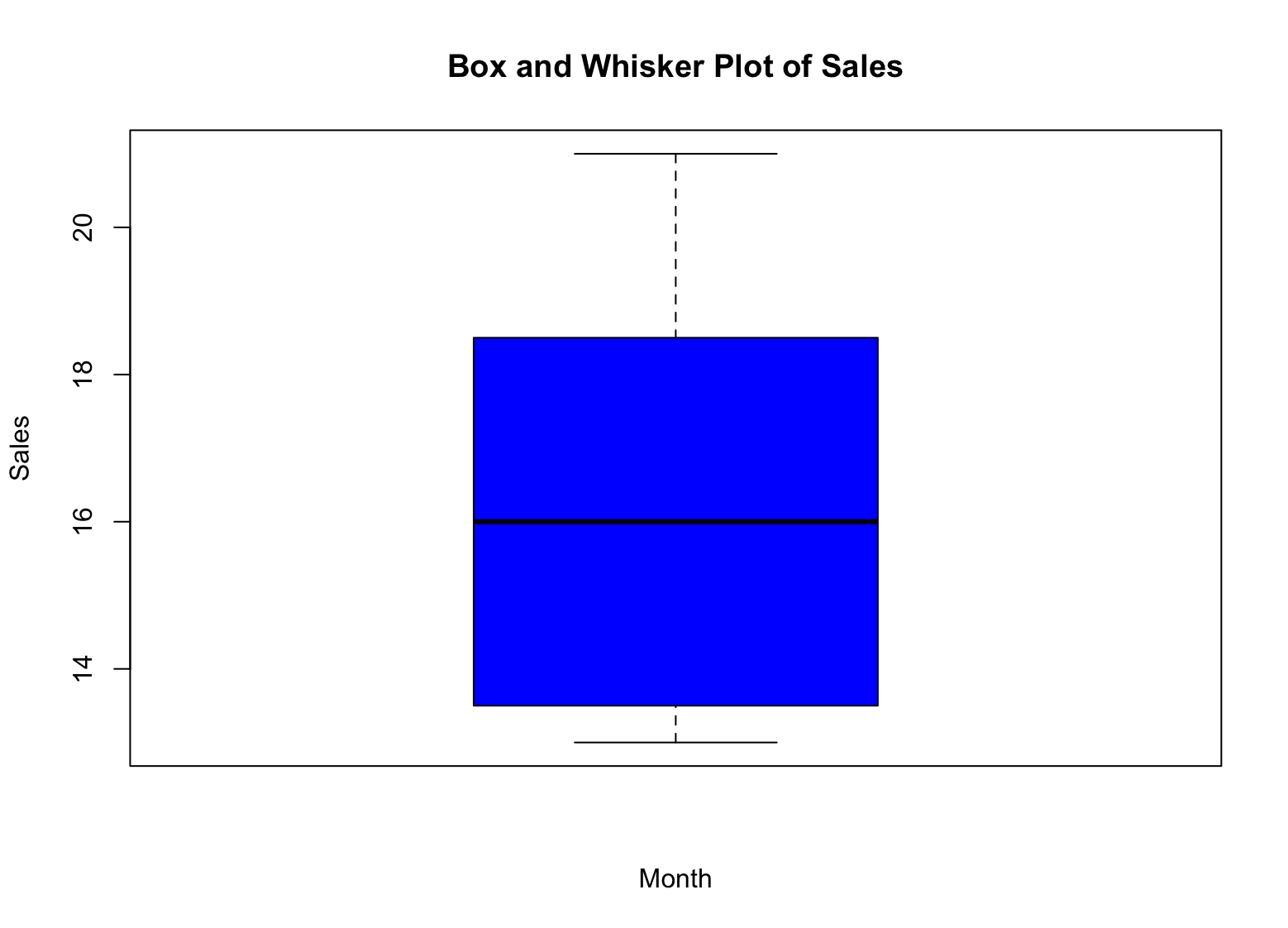
ตัวอย่าง Box Plot สำหรับ Descriptive Statistics ใน R
แล้วเราจะตีความ Box and Whisker Plot สำหรับข้อมูลยอดขายของเราอย่างไร? นี่คือวิธี:
-
กล่อง (Box) แทน Interquartile Range (IQR) ซึ่งเป็นช่วงระหว่าง Quartile แรกและที่สาม (Percentile ที่ 25 และ 75) ของข้อมูล ความสูงของกล่องแทน IQR
-
Median แสดงด้วยเส้นภายในกล่อง เป็นค่าที่แยกครึ่งบนและครึ่งล่างของข้อมูล
-
Whiskers แทนค่าต่ำสุดและสูงสุดของข้อมูล ยกเว้น Outliers ใดๆ Outliers แสดงเป็นจุดแต่ละจุดนอก Whiskers
-
Outliers แสดงเป็นจุดแต่ละจุดนอก Whiskers พวกเขาแทนค่าที่แตกต่างอย่างมีนัยสำคัญจากข้อมูลที่เหลือ
โดยการดูที่ Box and Whisker Plot ของข้อมูลยอดขาย คุณสามารถเห็นการกระจายของยอดขายสำหรับทั้งปีได้อย่างรวดเร็ว คุณสามารถเห็นว่า Median อยู่ที่ไหน รวมถึงช่วงของค่า (IQR) และ Outliers ที่อาจมี ข้อมูลนี้สามารถช่วยคุณตัดสินใจอย่างมีข้อมูลรองรับเกี่ยวกับข้อมูลของคุณและระบุพื้นที่ใดๆ ที่อาจต้องมีการสืบสวนเพิ่มเติม
คำถามที่พบบ่อย
สรุป
และนั่นคือทั้งหมด! เราหวังว่าคุณจะสนุกกับการเดินทางสู่โลกของ Descriptive Statistics ใน R เราได้ครอบคลุมเนื้อหาค่อนข้างมาก ตั้งแต่การคำนวณค่าสถิติเชิงพรรณนาที่สำคัญ เช่น Mean, Median, Mode, Range, Standard Deviation และ Variance ไปจนถึงการสร้างการแสดงผลด้วยภาพของข้อมูลของคุณโดยใช้ Box Plot, Scatter Plot และ Trend Line
เราหวังว่าคุณจะพบว่าบทความนี้มีประโยชน์และตอนนี้คุณมีความเข้าใจที่ดีขึ้นเกี่ยวกับวิธีการทำ Descriptive Statistics ใน R จำไว้ว่า Descriptive Statistics เป็นเพียงขั้นตอนแรกในกระบวนการวิเคราะห์ข้อมูลใดๆ ดังนั้นอย่าลังเลที่จะสำรวจเพิ่มเติมและดำดิ่งลึกลงไปในโลกของการวิเคราะห์ข้อมูล และนี่คือคำแนะนำที่ดี: ตัวอย่างง่ายๆ ของ Linear Regression ใน R
ดังนั้นไปข้างหน้าเลย สำรวจข้อมูลของคุณต่อไป และอย่าหยุดเรียนรู้! และเช่นเคย ขอให้วิเคราะห์ข้อมูลอย่างมีความสุข!