การทดสอบการแจกแจงปกติ (Normality Test) ใน R เป็นสิ่งสำคัญก่อนการวิเคราะห์ทางสถิติแบบ Parametric เช่น T-test, ANOVA หรือ Linear Regression การทดสอบเหล่านี้อาศัยสมมติฐานที่ว่าข้อมูลมีการแจกแจงแบบปกติ (Normal Distribution) และหากสมมติฐานนี้ถูกละเมิด อาจนำไปสู่ข้อสรุปที่ไม่ถูกต้อง
ในคู่มือนี้ เราจะครอบคลุมทั้งวิธีการแบบกราฟ (Histogram, QQ Plot) การทดสอบทางสถิติ (Shapiro-Wilk Test, Kolmogorov-Smirnov Test, Anderson-Darling Test) และวิธีการแปลผลการทดสอบการแจกแจงปกติใน R
การแจกแจงปกติคืออะไร?
การแจกแจงปกติ (Normality) หมายถึง ข้อมูลมีการกระจายตัวตามรูปแบบการแจกแจงแบบปกติ (Normal Distribution) การแจกแจงแบบปกติเรียกอีกชื่อว่า Gaussian Distribution มีลักษณะเป็นเส้นโค้งรูประฆังที่กำหนดโดยค่าเฉลี่ย (Mean) และส่วนเบี่ยงเบนมาตรฐาน (Standard Deviation) ค่าเฉลี่ยแสดงถึงจุดศูนย์กลางของการแจกแจง ในขณะที่ส่วนเบี่ยงเบนมาตรฐานแสดงถึงการกระจายตัวของข้อมูลรอบค่าเฉลี่ย
 รูปที่ 1: กราฟการแจกแจงแบบปกติ (Normal Distribution)
รูปที่ 1: กราฟการแจกแจงแบบปกติ (Normal Distribution)
การแจกแจงแบบปกติมีความสำคัญเนื่องจากการทดสอบทางสถิติแบบ Parametric หลายประเภท (T-test, ANOVA, Linear Regression) อาศัยสมมติฐานว่าข้อมูลที่วิเคราะห์มีการแจกแจงแบบปกติ หากข้อมูลของคุณละเมิดสมมติฐานการแจกแจงปกตินี้ การทดสอบทางสถิติเหล่านี้อาจให้ผลลัพธ์ที่ไม่ถูกต้องหรือข้อสรุปที่ไม่ถูกต้อง
วิธีการตรวจสอบการแจกแจงปกติด้วยกราฟใน R
วิธีการตรวจสอบด้วยกราฟให้ภาพที่เข้าใจง่ายในการประเมินว่าข้อมูลของคุณมีการแจกแจงแบบปกติหรือไม่ นี่คือสองวิธีการแบบกราฟที่ใช้กันทั่วไป:
1. Histogram
Histogram เป็นกราฟที่แสดงการกระจายความถี่ของข้อมูล หากข้อมูลมีการแจกแจงแบบปกติ Histogram จะแสดงเส้นโค้งรูประฆังที่สมมาตร
วิธีการสร้าง Histogram ใน R:
# สร้างข้อมูลตัวอย่าง
data <- rnorm(100)
# สร้าง Histogram
hist(data, main = "Histogram of Sample Data",
xlab = "Value", col = "lightblue")Code นี้สร้างตัวเลขสุ่ม 100 ตัวจากการแจกแจงแบบปกติมาตรฐาน (mean = 0, standard deviation = 1) โดยใช้ฟังก์ชัน rnorm() และสร้าง Histogram โดยใช้ฟังก์ชัน hist()
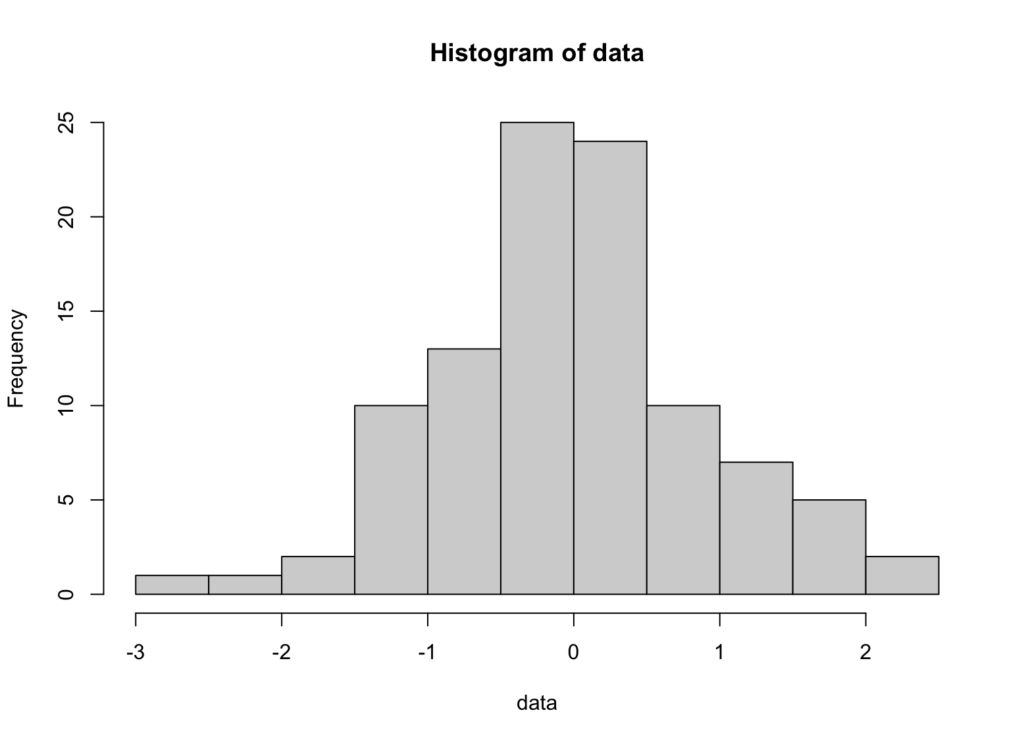 รูปที่ 2: Histogram แสดงข้อมูลที่มีการแจกแจงแบบปกติ
รูปที่ 2: Histogram แสดงข้อมูลที่มีการแจกแจงแบบปกติ
การแปลผล: หาก Histogram แสดงเส้นโค้งรูประฆังที่สมมาตรและอยู่ตรงกลางที่ค่าเฉลี่ย ข้อมูลของคุณน่าจะมีการแจกแจงแบบปกติ การแจกแจงที่เบ้ (Skewed) หรือมีหลายยอด (Multimodal) บ่งบอกถึงการเบี่ยงเบนจากการแจกแจงปกติ
2. QQ Plot (Quantile-Quantile Plot)
QQ Plot (Quantile-Quantile Plot) เปรียบเทียบ Quantiles ของข้อมูลของคุณกับ Quantiles ของการแจกแจงแบบปกติเชิงทฤษฎี เป็นหนึ่งในวิธีการแบบกราฟที่เชื่อถือได้ที่สุดในการประเมินการแจกแจงปกติ
วิธีการสร้าง QQ Plot ใน R:
# สร้างข้อมูลตัวอย่าง
data <- rnorm(100)
# สร้าง QQ Plot
qqnorm(data, main = "Normal Q-Q Plot")
qqline(data, col = "red")Code นี้สร้างตัวเลขสุ่ม 100 ตัวจากการแจกแจงแบบปกติมาตรฐานและสร้าง QQ Plot โดยใช้ฟังก์ชัน qqnorm() ฟังก์ชัน qqline() เพิ่มเส้นอ้างอิงที่แสดงถึงการแจกแจงแบบปกติที่สมบูรณ์แบบ
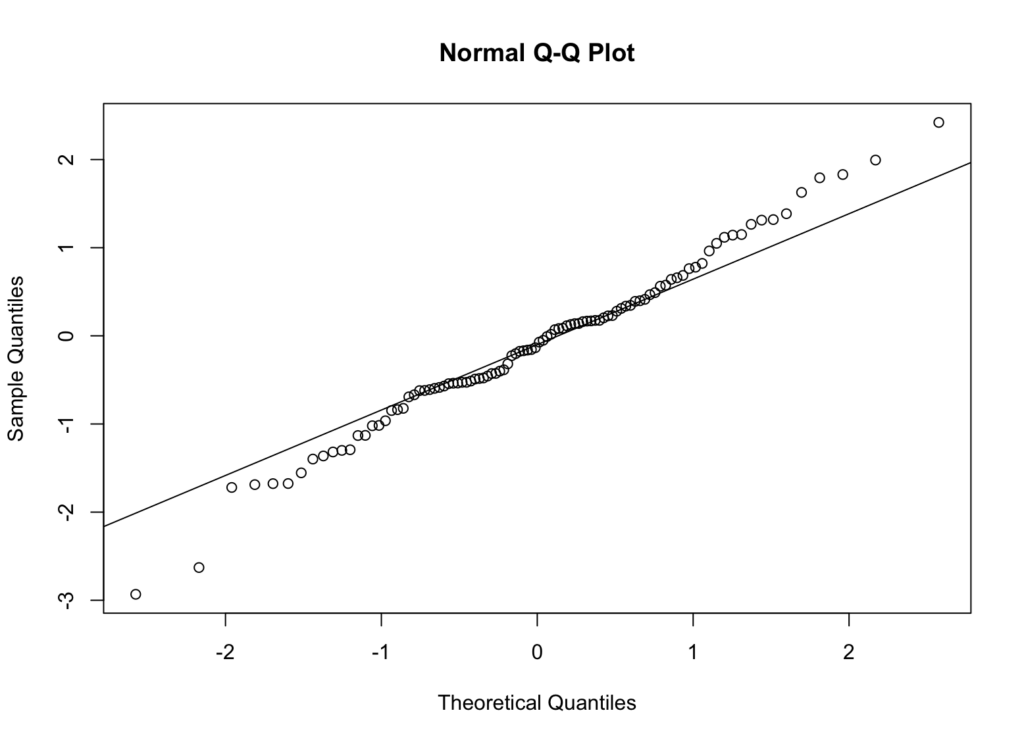 รูปที่ 3: QQ Plot สำหรับข้อมูลที่มีการแจกแจงแบบปกติ
รูปที่ 3: QQ Plot สำหรับข้อมูลที่มีการแจกแจงแบบปกติ
การแปลผล: หากข้อมูลของคุณมีการแจกแจงแบบปกติ จุดต่างๆ ควรตกอยู่ใกล้เส้นอ้างอิง การเบี่ยงเบนอย่างเป็นระบบจากเส้นบ่งบอกถึงการไม่เป็นปกติ:
- จุดโค้งขึ้นเหนือเส้นที่ปลายทั้งสองข้างบ่งบอกถึง Heavy Tails
- จุดโค้งลงใต้เส้นที่ปลายทั้งสองข้างบ่งบอกถึง Light Tails
- รูปแบบตัว S บ่งบอกถึงความเบ้ (Skewness)
การทดสอบทางสถิติสำหรับการแจกแจงปกติใน R
แม้ว่าวิธีการแบบกราฟจะมีประโยชน์ แต่การทดสอบทางสถิติให้การประเมินเชิงปริมาณที่เป็นกลางเกี่ยวกับการแจกแจงปกติ นี่คือการทดสอบการแจกแจงปกติที่ใช้กันทั่วไปใน R:
1. Shapiro-Wilk Test
Shapiro-Wilk Test เป็นหนึ่งในการทดสอบการแจกแจงปกติที่มีประสิทธิภาพมากที่สุด โดยเฉพาะสำหรับขนาดตัวอย่างเล็กถึงกลาง (n < 2000)
สมมติฐาน:
- สมมติฐานว่าง (H₀): ข้อมูลมีการแจกแจงแบบปกติ
- สมมติฐานทางเลือก (H₁): ข้อมูลไม่มีการแจกแจงแบบปกติ
วิธีการทำ Shapiro-Wilk Test ใน R:
# สร้างข้อมูลตัวอย่าง
data <- rnorm(100)
# ทำ Shapiro-Wilk Test
shapiro.test(data)Code นี้สร้างตัวเลขสุ่ม 100 ตัวจากการแจกแจงแบบปกติมาตรฐานและทำ Shapiro-Wilk Test โดยใช้ฟังก์ชัน shapiro.test()
 รูปที่ 4: ผลลัพธ์ Shapiro-Wilk Test
รูปที่ 4: ผลลัพธ์ Shapiro-Wilk Test
การแปลผล:
- p-value > 0.05: ไม่ปฏิเสธสมมติฐานว่าง ข้อมูลดูเหมือนมีการแจกแจงแบบปกติ
- p-value ≤ 0.05: ปฏิเสธสมมติฐานว่าง ข้อมูลเบี่ยงเบนจากการแจกแจงปกติอย่างมีนัยสำคัญ
หมายเหตุ: Shapiro-Wilk Test อาจไวเกินไปกับขนาดตัวอย่างขนาดใหญ่ โดยตรวจพบการเบี่ยงเบนเล็กน้อยจากการแจกแจงปกติที่มีผลกระทบเชิงปฏิบัติน้อย
2. Kolmogorov-Smirnov Test
Kolmogorov-Smirnov Test (K-S Test) เปรียบเทียบฟังก์ชันการแจกแจงสะสม (Cumulative Distribution Function) ของข้อมูลของคุณกับการแจกแจงแบบปกติเชิงทฤษฎี
# สร้างข้อมูลตัวอย่าง
data <- rnorm(100)
# ทำ Kolmogorov-Smirnov Test
ks.test(data, "pnorm", mean = mean(data), sd = sd(data))การแปลผล: คล้ายกับ Shapiro-Wilk Test ค่า p-value > 0.05 บ่งบอกว่าข้อมูลมีการแจกแจงแบบปกติ
หมายเหตุ: K-S Test มีประสิทธิภาพน้อยกว่า Shapiro-Wilk Test ในการตรวจจับการเบี่ยงเบนจากการแจกแจงปกติ โดยเฉพาะที่หาง (Tails) ของการแจกแจง
3. Anderson-Darling Test
Anderson-Darling Test ให้น้ำหนักกับหางของการแจกแจงมากกว่า Kolmogorov-Smirnov Test ทำให้ไวต่อการเบี่ยงเบนที่หางมากขึ้น
# ติดตั้งและโหลด Package ถ้าจำเป็น
# install.packages("nortest")
library(nortest)
# สร้างข้อมูลตัวอย่าง
data <- rnorm(100)
# ทำ Anderson-Darling Test
ad.test(data)การแปลผล: ค่า p-value > 0.05 บ่งบอกว่าข้อมูลสอดคล้องกับการแจกแจงแบบปกติ
การเลือก Normality Test ที่เหมาะสม
การทดสอบการแจกแจงปกติแต่ละแบบมีจุดแข็งที่แตกต่างกันและเหมาะสำหรับสถานการณ์ที่แตกต่างกัน:
Shapiro-Wilk Test:
- เหมาะสำหรับขนาดตัวอย่างเล็กถึงกลาง (n < 2000)
- การทดสอบการแจกแจงปกติที่มีประสิทธิภาพมากที่สุด
- อาจไวเกินไปกับตัวอย่างขนาดใหญ่
Kolmogorov-Smirnov Test:
- เหมาะสำหรับขนาดตัวอย่างทุกขนาด
- การทดสอบแบบอเนกประสงค์
- มีประสิทธิภาพน้อยกว่า Shapiro-Wilk Test
Anderson-Darling Test:
- ดีสำหรับการตรวจจับการเบี่ยงเบนที่หางของการแจกแจง
- ใช้ได้กับขนาดตัวอย่างทุกขนาด
- ต้องใช้ Package nortest
คำแนะนำ: สำหรับการใช้งานส่วนใหญ่ที่มีขนาดตัวอย่างต่ำกว่า 2,000 ให้ใช้ Shapiro-Wilk Test ร่วมกับ QQ Plot เพื่อการยืนยันด้วยภาพ
คำถามที่พบบ่อย (FAQ)
สรุป
การทดสอบการแจกแจงปกติใน R เป็นทักษะพื้นฐานสำหรับนักวิเคราะห์ข้อมูลและนักสถิติ คู่มือนี้ครอบคลุมทั้งวิธีการแบบกราฟ (Histogram และ QQ Plot) และการทดสอบทางสถิติ (Shapiro-Wilk Test, Kolmogorov-Smirnov Test และ Anderson-Darling Test) เพื่อประเมินว่าข้อมูลของคุณมีการแจกแจงแบบปกติหรือไม่
จำไว้ว่าควรใช้การผสมผสานของวิธีการต่างๆ: เริ่มต้นด้วยการตรวจสอบด้วยภาพโดยใช้ Histogram และ QQ Plot จากนั้นยืนยันด้วยการทดสอบทางสถิติเช่น Shapiro-Wilk Test การเข้าใจการแจกแจงปกติเป็นสิ่งสำคัญก่อนการวิเคราะห์ทางสถิติแบบ Parametric เนื่องจากการละเมิดสมมติฐานการแจกแจงปกติอาจนำไปสู่ข้อสรุปที่ไม่ถูกต้อง
สำหรับการใช้งานส่วนใหญ่ที่มีขนาดตัวอย่างต่ำกว่า 2,000 Shapiro-Wilk Test ร่วมกับการแสดงภาพ QQ Plot ให้การประเมินการแจกแจงปกติใน R ที่เชื่อถือได้ที่สุด