În lecția anterioară, am învățat cum să găsim Standard Deviation cu Excel. De data aceasta vom învăța cum să găsim Standard Deviation în R pas cu pas cu exemple clare.
Deși R oferă o serie de tipuri și structuri de date, în acest tutorial ne vom concentra pe cum să găsim Standard Deviation în RStudio pentru tipurile cel mai frecvent folosite, respectiv pentru data frames, vectori și arrays.
Presupunând că ai deja R și RStudio instalate pe computer, mergi înainte și lansează RStudio. Între timp, să revedem rapid câteva lucruri importante despre Standard Deviation – nu va dura mult.
Referință Rapidă: Standard Deviation în R
| Funcție | Folosit pentru | Sintaxă | Exemplu |
|---|---|---|---|
| sd() | Standard Deviation al eșantionului | sd(x) | sd(df$column) |
| sd() | Standard Deviation al populației | sd(x) * sqrt((n-1)/n) | sd(data) * sqrt(24/25) |
| var() | Variance (pentru calcul manual) | var(x) | sqrt(var(data)) |
Ce Este Standard Deviation?
În termeni simpli, Standard Deviation ne spune cât de dispersat este un set de puncte de date în raport cu media lor (average) într-un set de date dat. Un Standard Deviation mic este preferat deoarece ne spune că datele sunt mai de încredere fiind grupate în jurul mediei. În contrast, un Standard Deviation mare indică că punctele de date sunt dispersate pe un interval mai larg de valori.
Notația generală pentru Standard Deviation este sd. Totuși, Standard Deviation are două formule (precum și două notații), în funcție de dacă Standard Deviation este calculat pentru întreaga populație sau un eșantion din aceasta.
Simbolul pentru Standard Deviation al populației este reprezentat de litera greacă mică Sigma σ în timp ce notația pentru Standard Deviation al eșantionului este litera mai familiară s.
Formula Standard Deviation al Populației
Unde:
- σ = Standard Deviation al populației
- μ = media populației
- N = dimensiunea populației
Formula Standard Deviation al Eșantionului
Unde:
- s = Standard Deviation al eșantionului
- x̄ = media eșantionului
- n = dimensiunea eșantionului
- n-1 = corecția Bessel (gradele de libertate)
Există o cantitate considerabilă de confuzie despre Standard Deviation, notație, calcul și folosire corectă în cercetarea statistică. Din fericire pentru tine, am remedierea perfectă pentru asta! Dacă ești nesigur despre diferența dintre Standard Deviation al populației și eșantionului, citește mai întâi acel ghid și te vei simți încrezător când sari în ape fierbinți cu R.
Calculează Standard Deviation în R
În R, funcția dedicată pentru Standard Deviation este sd() și calculează practic rădăcina pătrată a varianței în obiectul de intrare. Obiectul și valorile pe care le conține vor fi definite mai întâi și apoi inserate ca obiecte de intrare în funcția sd() pentru calcul.
Important: Funcția sd() din R calculează Standard Deviation al eșantionului (folosind n-1 în numitor). Dacă ai nevoie de Standard Deviation al populației, va trebui să aplici un factor de corecție.
În continuare, să învățăm exact cum calculăm Standard Deviation în R folosind funcția încorporată sd() și câteva exemple pas cu pas.
Folosind Set de Date Excel
Să începem calculând Standard Deviation pentru vârstă în R pentru un grup de respondenți într-un set de date Excel.
Poți urma descărcând fișierul Standard-Deviation-on-R.xlsx din bara laterală. Odată descărcat, importă setul de date Excel în RStudio navigând la File → Import Dataset → From Excel și selectând fișierul descărcat.
Setul nostru de date Excel exemplu conține două coloane: age și weight așa cum se vede în imaginea următoare.
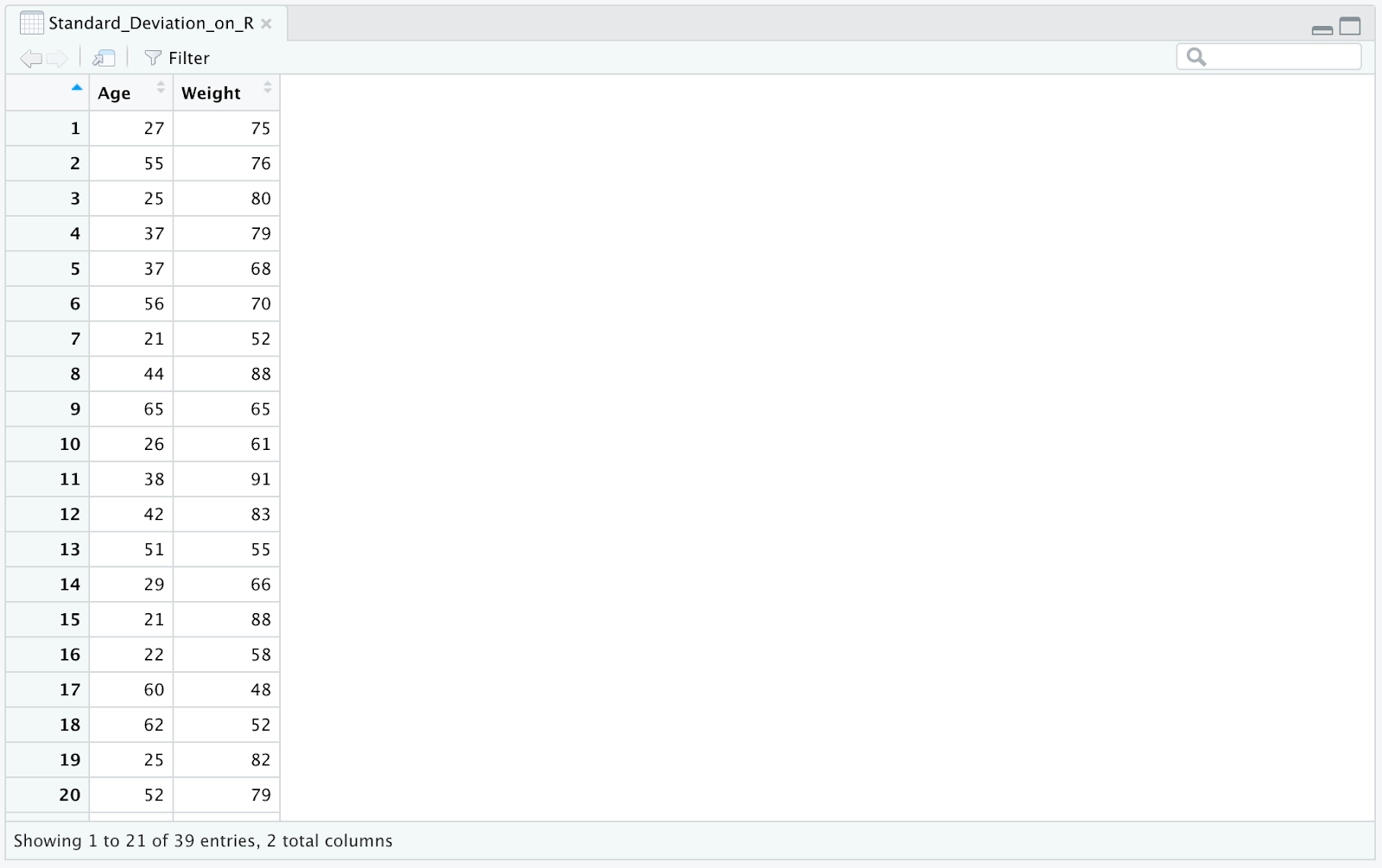
Pasul 1: Importă fișierul Excel
În RStudio, navighează la:
- File → Import Dataset → From Excel
- Selectează fișierul Standard-Deviation-on-R.xlsx
Pasul 2: Calculează Standard Deviation pentru coloana age
Pentru a găsi Standard Deviation în R pentru subsetul age din setul de date Excel importat, tastează în consola RStudio:
sd(Standard_Deviation_on_R$Age)Unde:
- sd() = funcția Standard Deviation în R
- Standard_Deviation_on_R = obiectul setului de date Excel
- $ = operator folosit pentru a extrage o parte specifică a unui obiect, de ex., coloana age
Și Standard Deviation pentru vârstă este 14.46402. Acum, mergi înainte și calculează Standard Deviation pentru subsetul weight din același fișier Excel.

Pasul 3: Calculează Standard Deviation pentru coloana weight
sd(Standard_Deviation_on_R$Weight)Folosind Data Frames
În R, data frames constau din trei componente: rows (rânduri), columns (coloane) și data (date). Pe scurt, data frames sunt tot ce poate stoca date tabulare.
Putem importa un data frame în R dintr-un fișier text sau Excel (așa cum am făcut anterior) sau putem crea un data frame manual și să extragem Standard Deviation al unei coloane numerice din el folosind funcția sd() în R.
Mai întâi, să creăm un data frame în R constând din cinci companii tech de top și prețul lor pe acțiune (NASDAQ) la momentul scrierii acestui articol:
| APPL | MSFT | AMZN | GOOGL | TSLA |
|---|---|---|---|---|
| 174.24 | 308.31 | 3259.95 | 2781.35 | 1078 |
Pasul 1: Creează data frame-ul
Vom folosi funcția data.frame() pentru a crea obiectul df în R. Acest data frame va avea cinci coloane și două rânduri, similar cu tabelul de mai sus, conținând ID-ul companiei (1 până la 5), numele companiei și prețul acțiunii pentru fiecare companie.
Iată cum creăm acest data frame în R folosind o singură comandă:
df <- data.frame(company_id = c(1:5),
company_name = c("APPL", "MSFT", "AMZN", "GOOGL", "TSLA"),
share_price = c(174.24, 308.31, 3259.95, 2781.35, 1078),
stringsAsFactors = FALSE)Unde:
- df = obiectul data frame conținând ID-ul companiei, numele companiei și prețul acțiunii celor mai mari cinci companii tech din SUA
- stringsAsFactors = un argument pentru funcția data.frame() și este folosit pentru a determina dacă string-urile dintr-un data frame ar trebui privite ca factori sau ca string-uri obișnuite. În acest caz, vrem să tratăm datele ca string-uri de caractere deci am adăugat flag-ul FALSE la argumentul stringsAsFactors
Pasul 2: Calculează Standard Deviation pentru coloana share_price
În final, să calculăm Standard Deviation în R pentru prețul acțiunii celor mai mari cinci companii tech din SUA folosind acum-faimoasa funcție R sd():
sd(df$share_price)
După cum vezi, Standard Deviation calculat pentru prețul acțiunii dat este 1422.415.
Desigur, putem adăuga rânduri și coloane suplimentare la un data frame și să extindem analiza noastră pentru Standard Deviation în R dincolo de doar prețul acțiunii.
Folosind Vectori
Un vector este cea mai de bază structură de date în R și constă dintr-o colecție de componente de date de același tip.
De exemplu, în R vectorul 1:10 va conține valorile de la 1 la 10 respectiv 1, 2, 3, 4, 5, 6, 7, 8, 9, 10.
În plus, un vector poate conține valori specifice de asemenea. De exemplu, vectorul c(2,4,6) va conține valorile 2, 4 și 6.
Pasul 1: Creează un vector
Să începem creând un vector vc folosind operatorul (:) și componente vector conținând valori de la 1 la 10.
vc <- 1:10Pasul 2: Vizualizează vectorul (opțional)
Poți vizualiza componentele vectorului vc folosind comanda concatenate cat după cum urmează:
cat(vc)Pasul 3: Calculează Standard Deviation
În continuare, calculează Standard Deviation în R pentru obiectul vc folosind comanda:
sd(vc)Iată output-ul complet. După cum putem vedea, Standard Deviation în R pentru vectorul vc este 3.02765

Folosind Arrays
În R, un array este o colecție de obiecte care poate purta două sau mai multe dimensiuni de date (multi-dimensional) și conține valori care sunt de același tip de date. Arrays-urile nu ar trebui confundate cu vectorii care sunt uni-dimensionali prin natură.
Pentru a găsi Standard Deviation pentru un array în R, trebuie să creăm array-ul folosind funcția încorporată array(). Pentru a face acest lucru, vom lua doi vectori ca argumente (de ex., vc1 și vc2) și apoi vom seta dimensiunile matricei folosind funcția dim.
Pasul 1: Creează primul vector
Mai întâi, să definim vectorul vc1 cu elementele 12 și 8 folosind comanda:
vc1 <- c(12,8)Pasul 2: Creează al doilea vector
Și configurează vectorul vc2 constând din elementele 39 și 17:
vc2 <- c(39,17)Pasul 3: Creează un array din vectori
În continuare, trebuie să creăm un array folosind vectorii vc1 și vc2 și să folosim funcția dim pentru a seta dimensiunile matricei (coloane după rânduri) după cum urmează:
arr <- array(c(vc1, vc2), dim = c(2, 2))Pasul 4: Calculează Standard Deviation pentru array
Și în final, putem folosi funcția sd() pentru a calcula Standard Deviation în R pentru obiectul array nou creat:
sd(arr)Mai jos este output-ul complet în R pentru comenzile de mai sus. După cum poți vedea, Standard Deviation pentru array-ul arr este 13.832
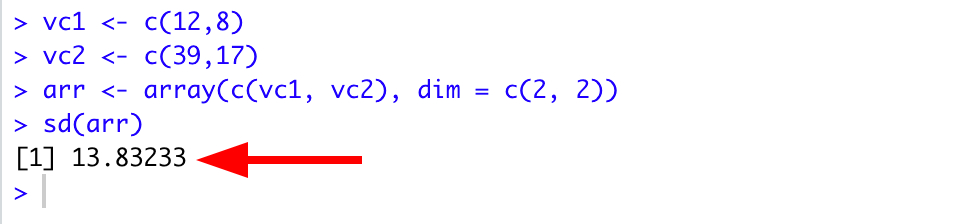
Standard Deviation al Populației vs. Eșantionului în R
După cum am menționat anterior, funcția sd() din R calculează Standard Deviation al eșantionului în mod implicit (folosind corecția Bessel cu n-1).
Dacă ai nevoie să calculezi Standard Deviation al populației în R, trebuie să aplici un factor de corecție:
# Standard Deviation al eșantionului (implicit)
sample_sd <- sd(data)
# Standard Deviation al populației
n <- length(data)
population_sd <- sd(data) * sqrt((n-1)/n)Exemplu: Standard Deviation al Populației
Să calculăm Standard Deviation al populației pentru exemplul nostru cu vector:
# Creează vector
vc <- 1:10
# Standard Deviation al eșantionului
sd(vc) # Returnează 3.02765
# Standard Deviation al populației
n <- length(vc)
sd(vc) * sqrt((n-1)/n) # Returnează 2.872281Întrebări Frecvente
Concluzie
În acest tutorial R pentru statistică, am învățat cum să calculăm Standard Deviation în RStudio pentru seturi de date Excel importate, data frames, vectori și arrays.
Deși calcularea Standard Deviation în SPSS sau Excel poate fi cumva mai directă, R ne oferă multă flexibilitate și control asupra datelor pe care le introducem și manipulăm.
Concluzii cheie:
- Funcția sd() este funcția încorporată a R pentru Standard Deviation
- R calculează Standard Deviation al eșantionului în mod implicit (folosind n-1)
- Folosește factorul de corecție
sd(x) * sqrt((n-1)/n)pentru Standard Deviation al populației - Operatorul $ extrage coloane din data frames
- Standard Deviation funcționează cu importuri Excel, data frames, vectori și arrays
Sper că ai găsit valoare în acest tutorial R. Dacă da, te rog ajută la răspândirea cunoștințelor partajând acest articol cu prietenii și colegii tăi.
Referințe
Field, A., Miles, J., & Field, Z. (2012). Discovering statistics using R. SAGE Publications.