เรียนรู้วิธีการวิเคราะห์และตีความผล Repeated Measures ANOVA ใน SPSS ด้วยคู่มือทีละขั้นตอนฉบับนี้ เราจะแนะนำคุณผ่านการวิเคราะห์ที่สมบูรณ์โดยใช้ข้อมูลจริง ตั้งแต่การตรวจสอบสมมติฐานไปจนถึงการตีความตารางผลลัพธ์จาก SPSS และการรายงานผลในรูปแบบ APA
คู่มือนี้ครอบคลุมทุกสิ่งที่คุณต้องการ: เมื่อใดควรใช้ Repeated Measures ANOVA, วิธีจัดการกับการละเมิด Sphericity (Mauchly's Test, Greenhouse-Geisser Correction), การตีความ Within-Subjects Effects และการทำ Pairwise Comparisons ดาวน์โหลดชุดข้อมูลสำหรับฝึกปฏิบัติจากด้านข้าง (รหัสผ่าน: uedufy) และติดตามไปด้วยกันเพื่อเชี่ยวชาญการทดสอบทางสถิติที่สำคัญนี้สำหรับการวิเคราะห์การวัดซ้ำ
สิ่งที่คุณจะได้เรียนรู้
เมื่อจบบทเรียนนี้ คุณจะสามารถ:
-
รู้ว่าเมื่อใดควรใช้ Repeated Measures ANOVA แบบ One-Way และ Two-Way
-
เข้าใจสมมติฐานของ Repeated Measures ANOVA
-
วิเคราะห์ One-Way ANOVA สำหรับ Repeated Measures ใน SPSS โดยใช้ Between-Subjects และ Within-Subject Factors
-
ตีความผลลัพธ์ของ Repeated Measures ANOVA ใน SPSS
มาเริ่มเรียนรู้สิ่งใหม่ๆ กันเลย!
เมื่อใดควรใช้ One-Way Repeated Measures ANOVA
ใช้ One-Way Repeated Measures ANOVA เมื่อคุณต้องการเปรียบเทียบค่าเฉลี่ยของกลุ่มผู้เข้าร่วมกลุ่มเดียวกันที่วัดสามครั้งขึ้นไปในช่วงเวลาที่แตกต่างกัน หรือภายใต้สามเงื่อนไขขึ้นไป
แตกต่างจาก T-test (ที่เปรียบเทียบค่าเฉลี่ยระหว่างสองกลุ่มหรือสองช่วงเวลา), Repeated Measures ANOVA สามารถจัดการกับการวัดหลายครั้งจากผู้เข้าร่วมกลุ่มเดียวกัน
ข้อกำหนดสำหรับ One-Way Repeated Measures ANOVA:
การศึกษาของคุณควรมีลักษณะดังนี้:
-
กลุ่มผู้ตอบแบบสอบถามหนึ่งกลุ่มที่วัดโดยใช้มาตรวัดเดียวกันในสามช่วงเวลาขึ้นไป หรือผู้เข้าร่วมแต่ละคนที่วัดโดยใช้อย่างน้อยสามข้อคำถามที่แตกต่างกัน (เช่น คำถาม) โดยใช้มาตรวัดการตอบสนองเดียวกัน
-
ตัวแปรอิสระเชิงหมวดหมู่หนึ่งตัว (เรียกอีกอย่างว่า Repeated Factor)
-
ตัวแปรตามแบบต่อเนื่องหนึ่งตัวที่ใช้สำหรับการสังเกตซ้ำ เรียกอีกอย่างว่า Repeated Measure
สับสนใช่ไหม? มาทำความเข้าใจโดยดูตัวอย่างกรณีศึกษาการออกแบบ Repeated Measure กันต่อ
สมมติว่าเราต้องการทดสอบประสิทธิผลของโปรแกรมลดน้ำหนักสองแบบ (เช่น แบบคาร์โบไฮเดรตต่ำและไขมันต่ำ) และ 3 ช่วงเวลาซ้ำ: ช่วงที่ 1 (ก่อนเริ่มอาหาร); ช่วงที่ 2 (หลัง 30 วัน), และช่วงที่ 3 (หลัง 90 วัน)
เราสามารถออกแบบการศึกษานี้ให้รวม 50 ผู้เข้าร่วม แบ่งเป็น สองกลุ่มๆ ละ 25 คน ผู้เข้าร่วมสามารถเป็นส่วนหนึ่งของกลุ่มเดียวเท่านั้นและจะใช้โปรแกรมอาหารเพียงโปรแกรมเดียวกับแต่ละกลุ่ม
นี่คือรูปแบบชุดข้อมูลสำหรับกรณีศึกษานี้ในแท็บ Data View ของ SPSS:
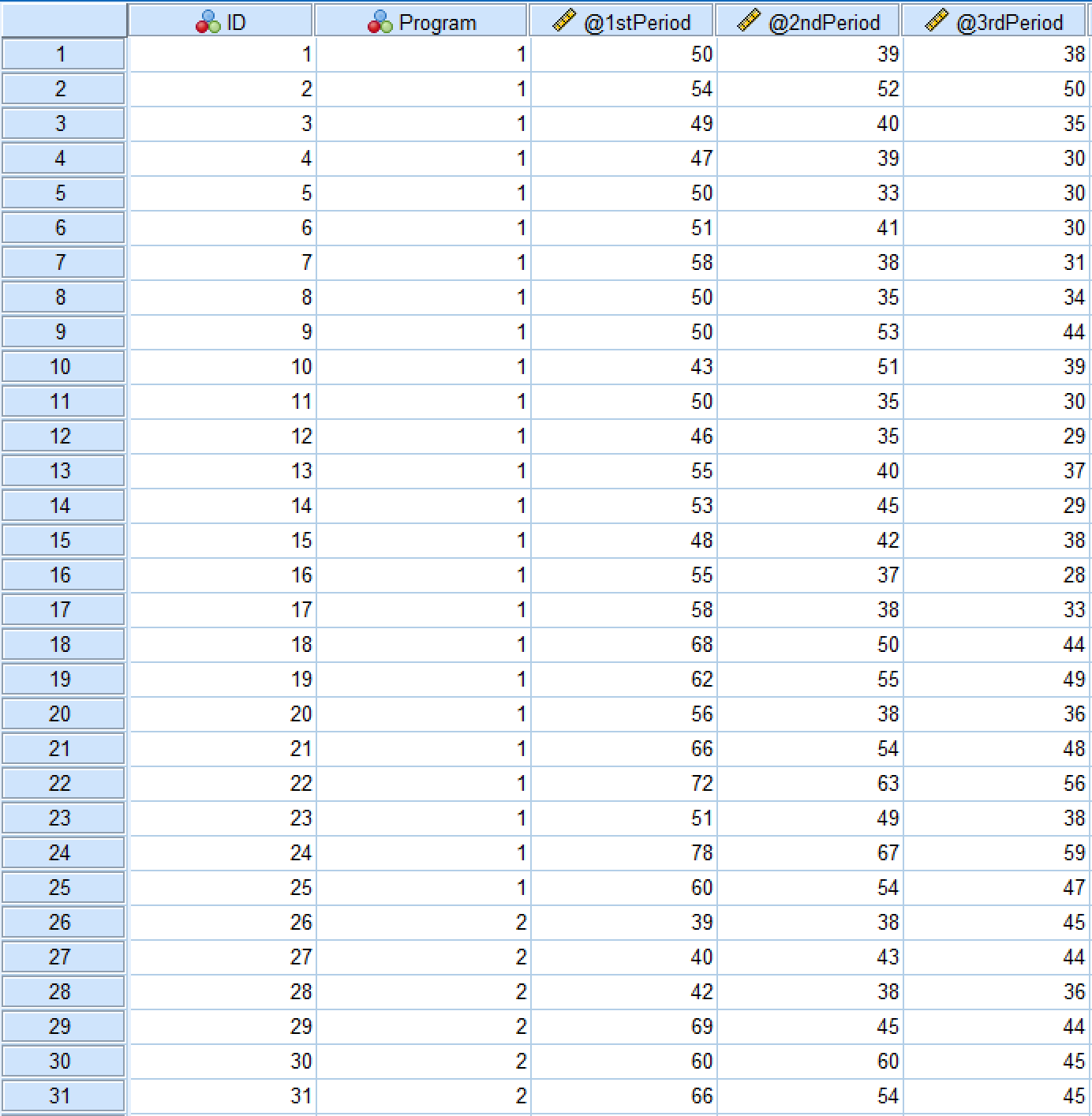 Data View ของ SPSS แสดง ANOVA สำหรับ Repeated Measures และโครงสร้างชุดข้อมูล
Data View ของ SPSS แสดง ANOVA สำหรับ Repeated Measures และโครงสร้างชุดข้อมูล
และนี่คือแท็บ Variable View ใน SPSS:
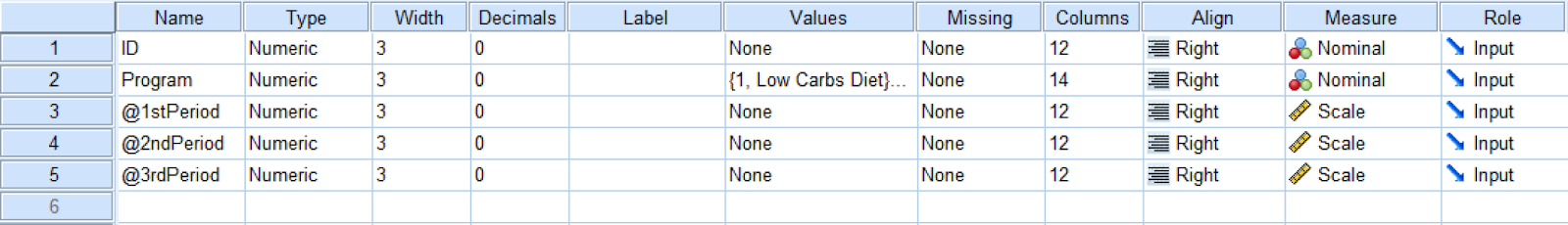 Variable View ของ Repeated Measures ANOVA ใน SPSS
Variable View ของ Repeated Measures ANOVA ใน SPSS
ตัวแปรอิสระในตัวอย่างนี้คือ [diet] Program ซึ่งประกอบด้วยสองระดับ: อาหารคาร์โบไฮเดรตต่ำและไขมันต่ำ ตัวแปรตามคือช่วงที่ 1, ช่วงที่ 2 และช่วงที่ 3 นอกจากนี้เรายังมี ID ซึ่งผู้ตอบแบบสอบถามแต่ละคนในการศึกษาจะเชื่อมโยงกับหมายเลขเฉพาะ
เนื่องจากการศึกษานี้มีตัวแปรอิสระหนึ่งตัวและเราวางแผนที่จะวัดผลกระทบของอาหารสำหรับผู้เข้าร่วมคนเดียวกันในสองกลุ่มที่แตกต่างกันในสามช่วงเวลา One-Way ANOVA สำหรับ Repeated Measures จึงเป็นแนวทางที่เหมาะสม
สมมติฐานของ Repeated Measures ANOVA
ก่อนที่จะวิเคราะห์ Repeated Measures ANOVA ให้ตรวจสอบว่าข้อมูลของคุณเป็นไปตามสมมติฐานหลักเหล่านี้:
1. Independence of Observations (ความเป็นอิสระของการสังเกต)
การสังเกตทั้งหมดต้องเป็นอิสระ - ผู้เข้าร่วมแต่ละคนสามารถอยู่ได้เพียงกลุ่มเดียวเท่านั้น และผู้เข้าร่วมไม่สามารถมีอิทธิพลต่อการตอบสนองของกันและกันได้
วิธีตรวจสอบ: ตรวจสอบว่าการออกแบบการวิจัยของคุณทำให้แน่ใจว่าผู้เข้าร่วมมีความเป็นอิสระ นี่เป็นปัญหาของการออกแบบ ไม่ใช่การทดสอบทางสถิติ
2. Sphericity (ความเท่าเทียมของความแปรปรวน)
ความแปรปรวนของความแตกต่างระหว่างคู่ทั้งหมดที่เป็นไปได้ของเงื่อนไข Within-Subjects ต้องเท่ากัน
วิธีตรวจสอบใน SPSS: Mauchly's Test of Sphericity (SPSS คำนวณโดยอัตโนมัติ)
- ถ้า p > .05: สมมติฐานผ่าน ใช้ F-test มาตรฐาน
- ถ้า p < .05: สมมติฐานถูกละเมิด ใช้การแก้ไข Greenhouse-Geisser หรือ Huynh-Feldt
3. Normality (การแจกแจงปกติ)
ตัวแปรตามควรมีการแจกแจงแบบปกติโดยประมาณสำหรับแต่ละระดับของ Within-Subjects Factor
วิธีตรวจสอบใน SPSS:
- การตรวจสอบด้วยสายตา: Q-Q Plots, Histograms
- การทดสอบทางสถิติ: Shapiro-Wilk Test สำหรับแต่ละช่วงเวลา
- สำหรับกลุ่มตัวอย่างขนาดใหญ่ (n > 30), ANOVA มีความทนทานต่อการละเมิดเล็กน้อย
สำคัญ: Repeated Measures ANOVA ค่อนข้างทนทานต่อการละเมิดความเป็นปกติ โดยเฉพาะกับกลุ่มตัวอย่างขนาดใหญ่ (n > 30)
ตอนนี้คุณเข้าใจสมมติฐานแล้ว มาวิเคราะห์ใน SPSS กันเลย!
วิเคราะห์ One-Way ANOVA สำหรับ Repeated Measures ใน SPSS [ฝึกปฏิบัติ]
นำเข้าชุดข้อมูลที่คุณดาวน์โหลดไว้ก่อนหน้านี้ใน SPSS โดยไปที่ Open → Data และเลือกไฟล์ .sav หรือเพียงแค่ดับเบิลคลิกที่ไฟล์ .sav เพื่อเปิดโดยอัตโนมัติใน SPSS
นี่คือขั้นตอนการวิเคราะห์ One-Way Repeated Measures ANOVA ใน SPSS:
-
ไปที่ Analyze → General Linear Model → Repeated Measures ในเมนูด้านบนของ SPSS
-
ในหน้าต่าง Repeated Measure Define Factor(s) ระบุ:
-
Within-Subject Factor Name เช่น Period หรือ Time Frame คุณสามารถเปลี่ยนชื่อเป็นสิ่งที่เหมาะสมในกรณีที่จำเป็น
-
Number of Levels ตามจำนวนตัวแปรตามในการศึกษา ในกรณีของเรา นี่คือสาม
-
คลิกปุ่ม Add เพื่อย้าย Factor และตัวแปรที่กำหนดไว้ไปยังกล่องที่เกี่ยวข้อง
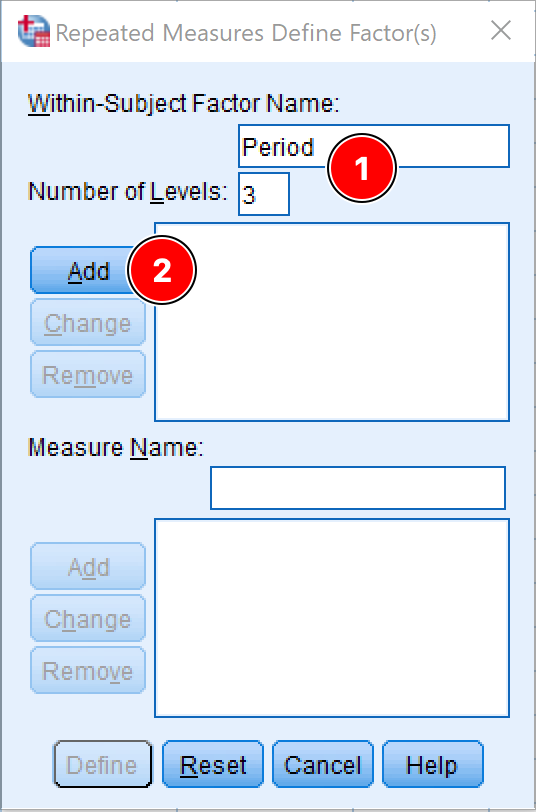 การกำหนด Within-Subject Factor สำหรับ Repeated Measures ANOVA ใน SPSS
การกำหนด Within-Subject Factor สำหรับ Repeated Measures ANOVA ใน SPSS
- คลิกปุ่ม Define
 คลิก Define เพื่อดำเนินการตั้งค่า Repeated Measures ANOVA
คลิก Define เพื่อดำเนินการตั้งค่า Repeated Measures ANOVA
- ในหน้าต่าง Repeated Measures ระบุตัวแปรตามในลำดับที่ถูกต้องสำหรับแต่ละตำแหน่ง Within-Subjects Variables
ในชุดข้อมูลตัวอย่าง SPSS ของเรา เรามีตัวแปรตามสามตัวที่แสดงถึงสามช่วงเวลา: ช่วงที่ 1, ช่วงที่ 2 และช่วงที่ 3
กำหนดแต่ละตัวแปรไปยังตำแหน่งที่เกี่ยวข้อง:
- ช่วงที่ 1 → ตำแหน่ง (1)
- ช่วงที่ 2 → ตำแหน่ง (2)
- ช่วงที่ 3 → ตำแหน่ง (3)
คุณสามารถเลือกแต่ละตัวแปรและใช้ปุ่มลูกศรเพื่อย้ายไปยังกล่องที่เหมาะสม หรือเพียงแค่ลากและวางแต่ละตัวแปรตามไปยังตำแหน่งของมัน
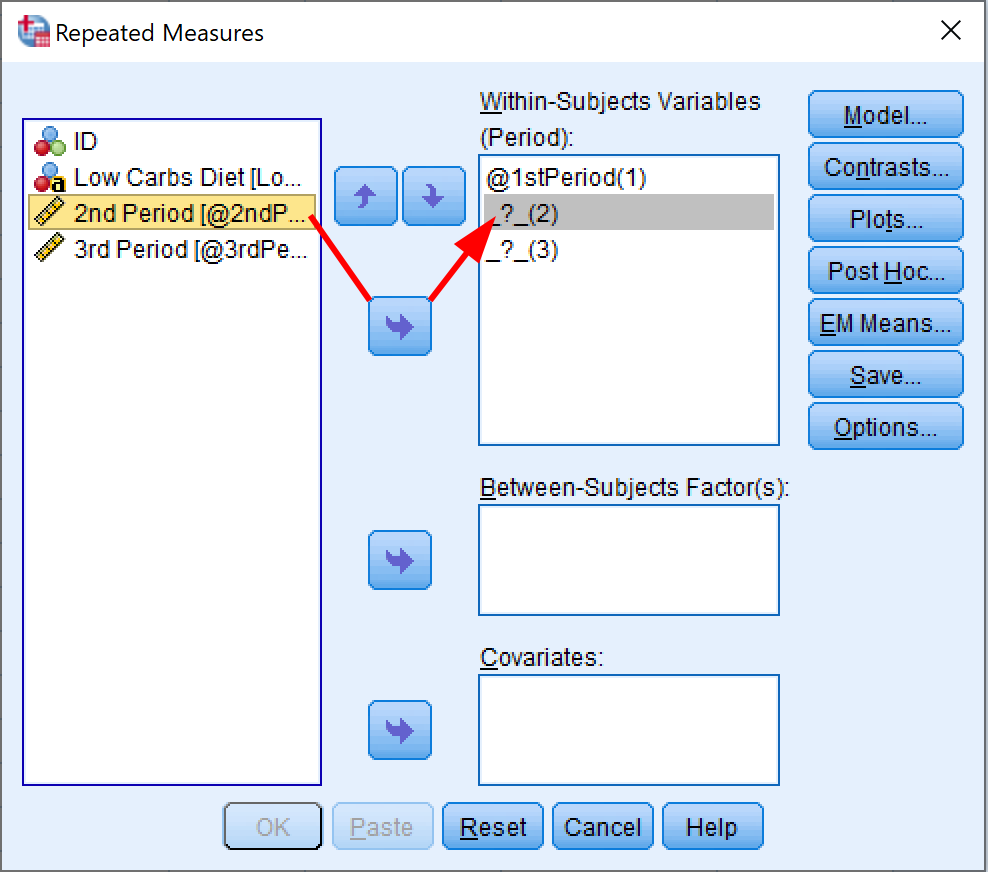 การเพิ่ม Within-Subjects Variables ใน SPSS สำหรับ Repeated Measures ANOVA
การเพิ่ม Within-Subjects Variables ใน SPSS สำหรับ Repeated Measures ANOVA
- เพิ่มตัวแปรอิสระที่สนใจไปยังกล่อง Between-Subject Factor(s) ในกรณีของเรา ตัวแปรอิสระคือ Program
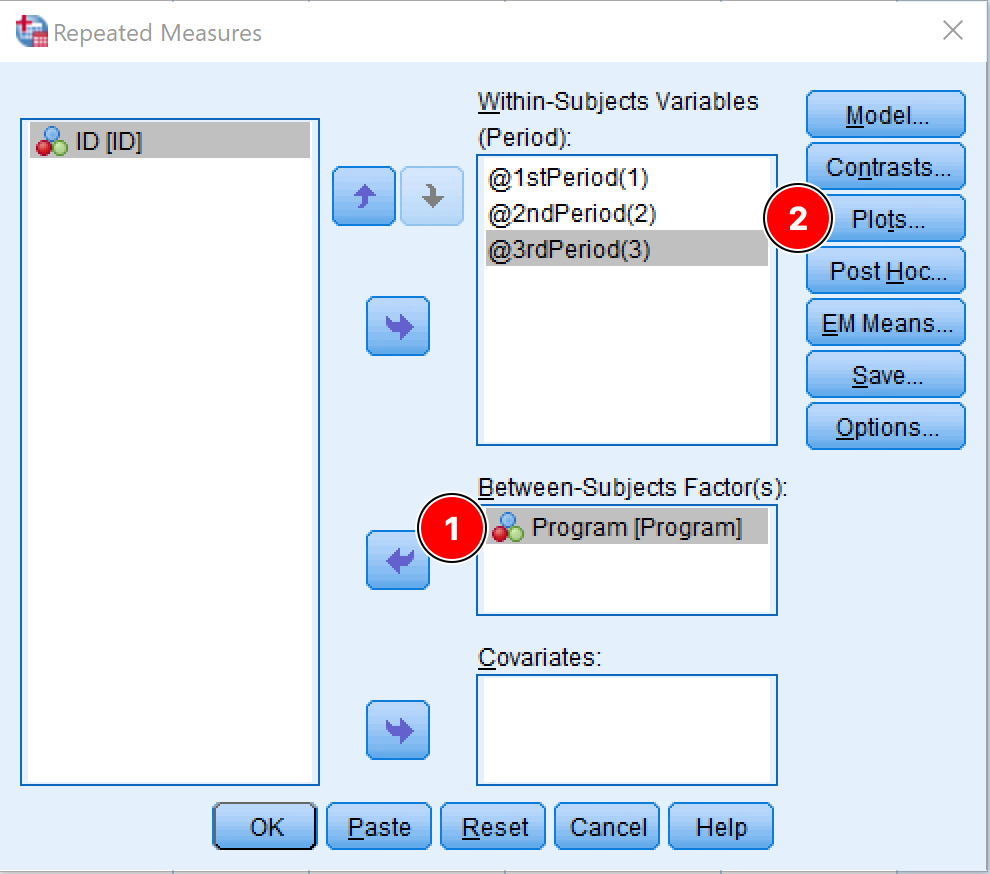 การเพิ่ม Between-Subjects Factor (Program) ใน SPSS
การเพิ่ม Between-Subjects Factor (Program) ใน SPSS
ก่อนที่เราจะดำเนินการต่อกับ One-Way ANOVA สำหรับ Repeated Measures ใน SPSS เราจำเป็นต้องเปลี่ยนการตั้งค่าบางอย่างสำหรับการวิเคราะห์ คลิกที่ปุ่ม Plots
- ในหน้าต่าง Profile Plots ย้าย Independent Factor (Program) ไปที่กล่อง Horizontal Axis และ Dependent Factor (Period) ไปที่กล่อง Separate Lines คลิกปุ่ม Add
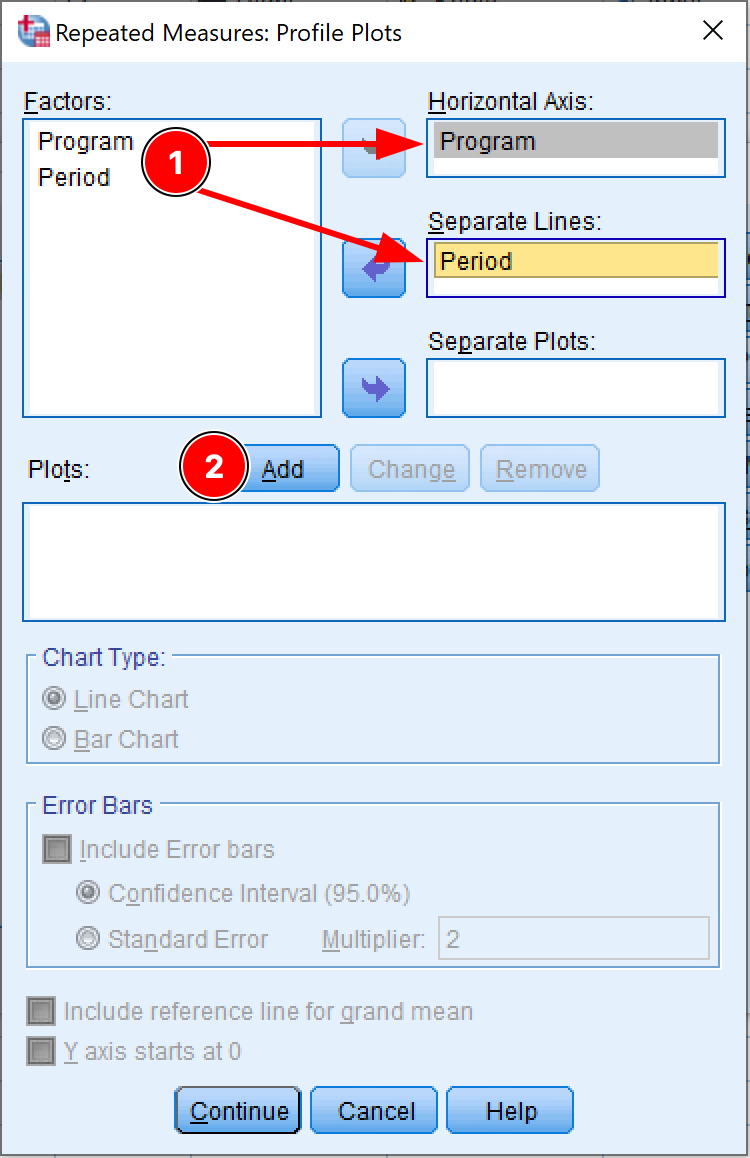 การตั้งค่า Profile Plots สำหรับ Repeated Measures ANOVA ใน SPSS
การตั้งค่า Profile Plots สำหรับ Repeated Measures ANOVA ใน SPSS
กล่อง Plots จะถูกเติมข้อมูล ตัวอย่างเช่น สำหรับชุดข้อมูลของเรา กราฟควรเป็น Program*Period ตามรูปภาพด้านล่าง
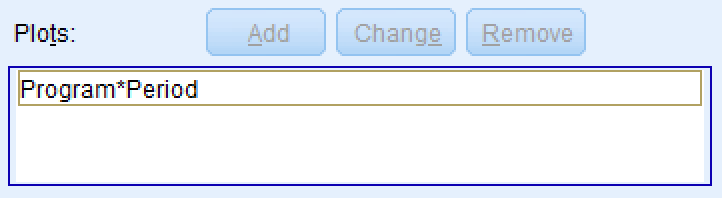 ยืนยันว่า Program*Period Interaction Plot ได้ถูกเพิ่มแล้ว
ยืนยันว่า Program*Period Interaction Plot ได้ถูกเพิ่มแล้ว
คลิก Continue คุณควรกลับมาที่หน้าต่าง Repeated Measures
เนื่องจากเรามีเพียงสองระดับสำหรับตัวแปรอิสระ (Low Carbs และ Low Fat Diets) เราจึงไม่จำเป็นต้องทำ Post Hoc Test (เรียกอีกอย่างว่า Multiple Comparison Test) อย่างไรก็ตาม หากการวิเคราะห์ ANOVA สำหรับ Repeated Measures ประกอบด้วยสามกลุ่มขึ้นไป Post Hoc Test จำเป็นเพื่อตรวจสอบว่ากลุ่มใดมีค่าเฉลี่ยที่แตกต่างและควบคุม Familywise Error Rate นี่คือกรณีเฉพาะเมื่อ ANOVA P-value มีนัยสำคัญสำหรับค่าเฉลี่ยของกลุ่มทั้งหมด
-
ถัดไป คลิกปุ่ม EM Means (Estimated Marginal Means) ที่นี่เราต้องปรับการตั้งค่าต่อไปนี้:
-
เราต้องการดูค่าเฉลี่ยสำหรับตัวแปรตาม ดังนั้นย้าย Period ไปยังกล่อง Display Means
-
เลือกช่องทำเครื่องหมาย Compare main effects
-
เลือก Bonferroni ในเมนูแบบเลื่อนลง Confidence interval adjustment
Bonferroni Correction เป็นวิธีที่ง่ายที่สุดในการควบคุมความเสี่ยงของการเผชิญกับ Type I Error (False-Positive) และการปฏิเสธสมมติฐานว่างเมื่อมันเป็นจริงจริงๆ
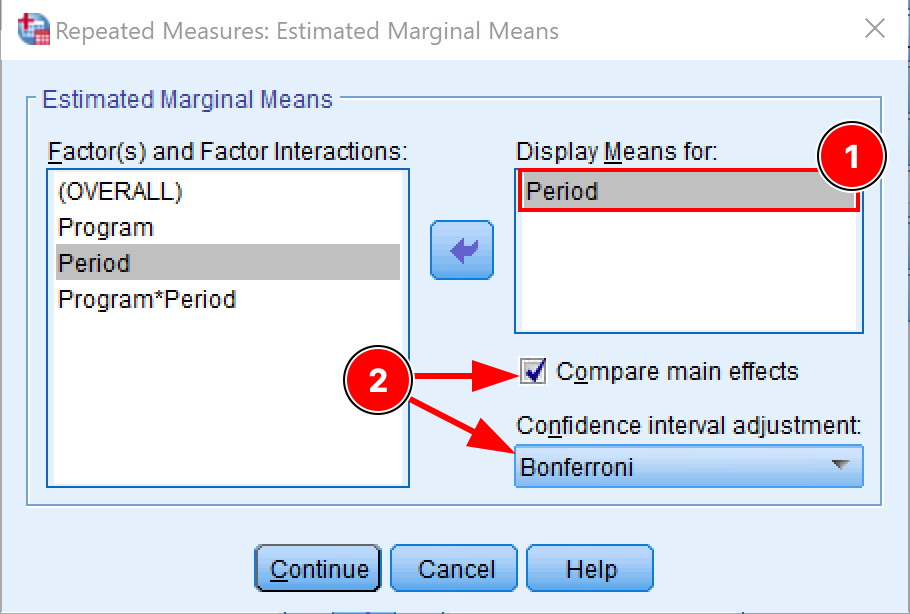 การกำหนดค่า Estimated Marginal Means พร้อม Bonferroni Correction ใน SPSS
การกำหนดค่า Estimated Marginal Means พร้อม Bonferroni Correction ใน SPSS
คลิก Continue เพื่อบันทึกการตั้งค่าและออกจากหน้าต่าง EM Means
-
[ทางเลือก] เมื่ออยู่ในหน้าต่าง Repeated Measures คลิกปุ่ม Options และตรวจสอบให้แน่ใจว่าช่องทำเครื่องหมายต่อไปนี้ถูกเลือก:
-
Descriptive statistics
-
Estimates of effect size
-
Homogeneity tests
คลิก Continue เพื่อบันทึกการตั้งค่าและออกจากหน้าต่าง Options
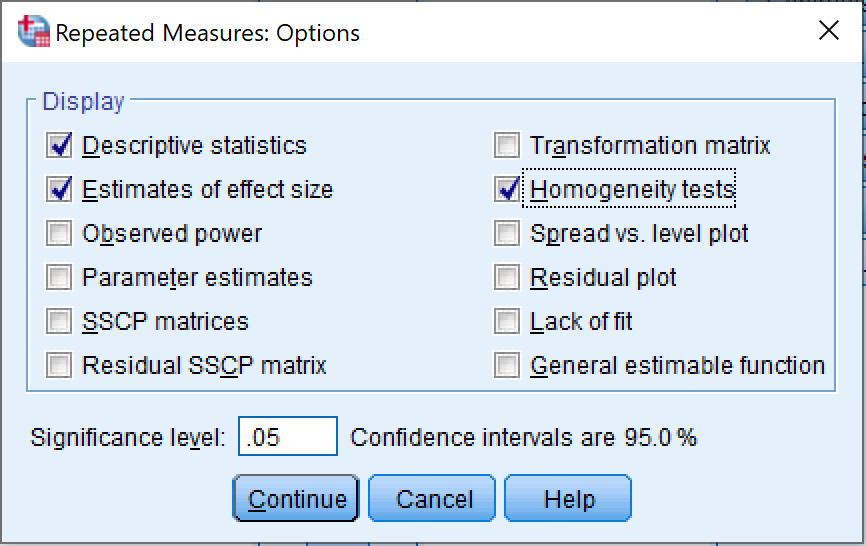 การเลือกตัวเลือกการแสดงผลสำหรับผลลัพธ์ Repeated Measures ANOVA ใน SPSS
การเลือกตัวเลือกการแสดงผลสำหรับผลลัพธ์ Repeated Measures ANOVA ใน SPSS
- สุดท้าย ในหน้าต่าง Repeated Measures คลิก OK เพื่อดำเนินการวิเคราะห์ ANOVA สำหรับ Repeated Measures ใน SPSS
ตีความผลลัพธ์ ANOVA สำหรับ Repeated Measures ใน SPSS
- ตารางแรกในผลลัพธ์ ANOVA Repeated Measures คือ Within-Subjects Factors ซึ่งแสดงโดยสามช่วงเวลา คือช่วงที่ 1, ช่วงที่ 2 และช่วงที่ 3 ในตัวอย่างของเรา
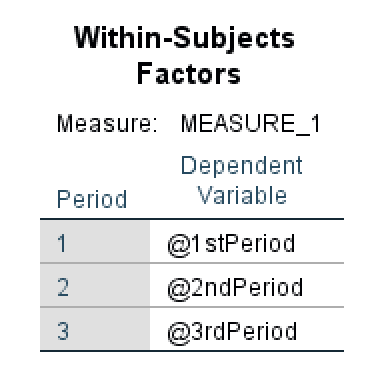 ตาราง Within-Subjects Factors ใน SPSS
ตาราง Within-Subjects Factors ใน SPSS
- ตาราง Between-Subjects Factors แสดงการทดลอง (เงื่อนไข) ที่ใช้กับผู้เข้าร่วม ในตัวอย่างของเรา เงื่อนไขเหล่านี้คือ Low Carbs Diet และ Low Fat Diet เรายังสามารถสังเกตได้ว่าจำนวนประชากร N เท่ากันสำหรับทั้งสองการทดลอง (N = 25 ผู้เข้าร่วม)
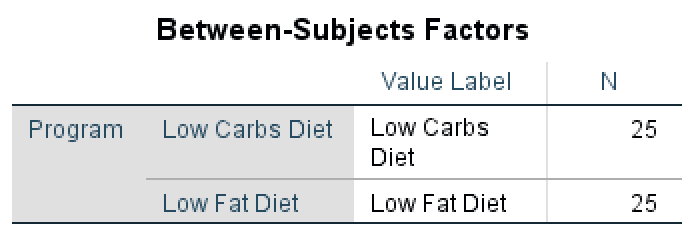 ผลลัพธ์ Between-Subjects Factors ใน SPSS แสดงขนาดกลุ่มที่เท่ากัน
ผลลัพธ์ Between-Subjects Factors ใน SPSS แสดงขนาดกลุ่มที่เท่ากัน
- ในตาราง Descriptive Statistics เราสามารถเห็นได้ว่าค่าเฉลี่ยโดยรวมสูงกว่าในช่วงที่ 1 (Total Mean = 54.76) ตามด้วยช่วงที่ 2 (Total Mean = 45.74) และช่วงที่ 3 (42.16) ซึ่งสามารถบอกถึงความเชื่อมโยงระหว่างโปรแกรมอาหารและการลดน้ำหนักของผู้เข้าร่วม
นอกจากนี้ เมื่อเราดูที่ค่าเฉลี่ยระหว่างกลุ่มสำหรับแต่ละโปรแกรมอาหาร เราสามารถสังเกตได้ว่าค่าเฉลี่ยสำหรับกลุ่ม Low Carbs Diet ต่ำกว่ากลุ่ม Low Fat Diet ซึ่งอาจบอกว่าโปรแกรมอาหารคาร์โบไฮเดรตต่ำมีประสิทธิภาพมากกว่า – ยกเว้นช่วงที่ 1 ที่ค่าเฉลี่ยระหว่างสองโปรแกรมใกล้เคียงกันที่สุด
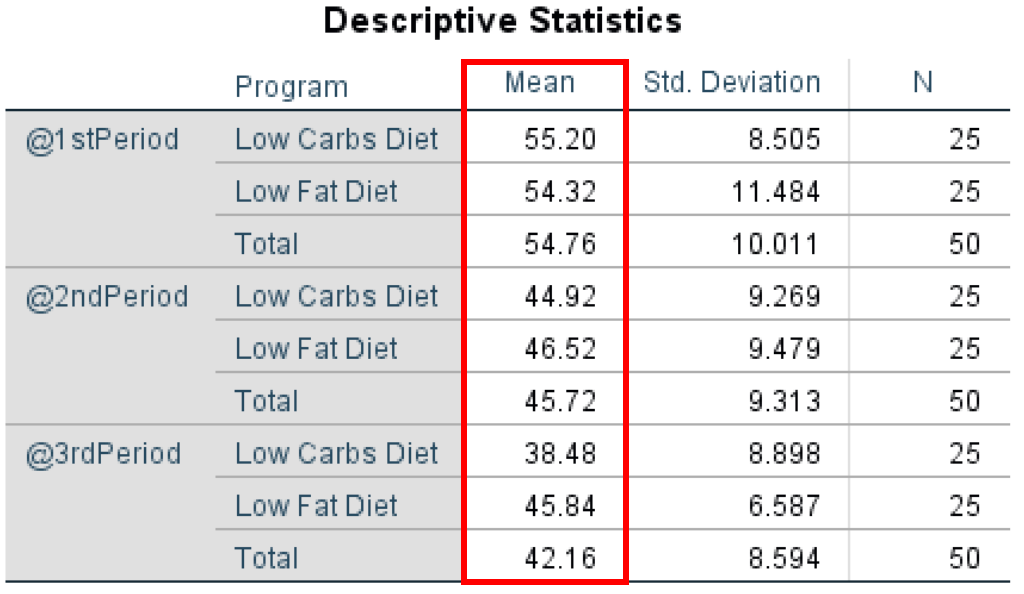 สถิติเชิงพรรณนาแสดงค่าเฉลี่ยและ Standard Deviations สำหรับแต่ละกลุ่มและช่วงเวลา
สถิติเชิงพรรณนาแสดงค่าเฉลี่ยและ Standard Deviations สำหรับแต่ละกลุ่มและช่วงเวลา
- Box's Test of Equality of Covariance Matrices (เรียกอีกอย่างว่า Box's M Test) เป็นการทดสอบพารามิเตอร์สำหรับเปรียบเทียบความแปรปรวนในกลุ่มตัวอย่างหลายตัวแปร การทดสอบนี้ตรวจสอบอย่างชัดเจนเพื่อดูว่า Covariance Matrices สองตัวหรือมากกว่ามีความเป็นเนื้อเดียวกัน (เท่ากัน)
ดังที่เห็นในผลลัพธ์ด้านล่าง ผลลัพธ์ Box's Test คือ 14.961 และ Significance P-value คือ 0.030 สิ่งสำคัญคือต้องจำไว้ว่า Box's Test มีระดับ α คือ 0.01 (มีนัยสำคัญถ้า < 0.01) ดังนั้นเราจึงมี Box's Test ที่มีผลลัพธ์ไม่มีนัยสำคัญทางสถิติที่ 0.030 ดังนั้นเราไม่สามารถปฏิเสธสมมติฐานว่างได้และเป็นไปตามสมมติฐาน Equal Population Covariance Matrices
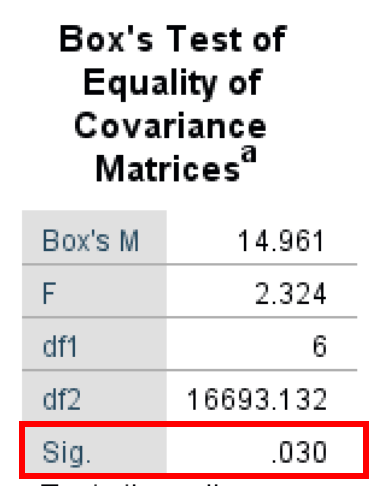 Box's M Test ประเมินความเท่าเทียมของ Covariance Matrices
Box's M Test ประเมินความเท่าเทียมของ Covariance Matrices
- Multivariate Test แสดงให้เราเห็นความแตกต่างของค่าเฉลี่ยโดยรวมใน Repeated Measures Multivariate Test หมายถึง Observational Independence และ Multivariate Normality ข้อดีอย่างหนึ่งของการใช้ Multivariate Test คือไม่ต้องการ Sphericity เหมือนกับแนวทาง Univariate – ตามกรณีในตัวอย่างนี้
Multivariate Test ดำเนินการโดยใช้สถิติการทดสอบที่แตกต่างกันสี่แบบ (Pillai's Trace, Wilks' Lambda, Hotelling's Trace และ Roy's Largest Root) ซึ่งให้ข้อมูลเหมือนกันโดยพื้นฐาน ตัวชี้วัดที่สำคัญที่สุดที่นี่คือ P-value (คอลัมน์ Sig.) ด้วยค่าข้ามสถิติการทดสอบทั้งหมดสำหรับ Period และ Period*Program ที่ 0.000 ดังนั้นจึงมีนัยสำคัญทางสถิติ (มีนัยสำคัญถ้า < 0.05)
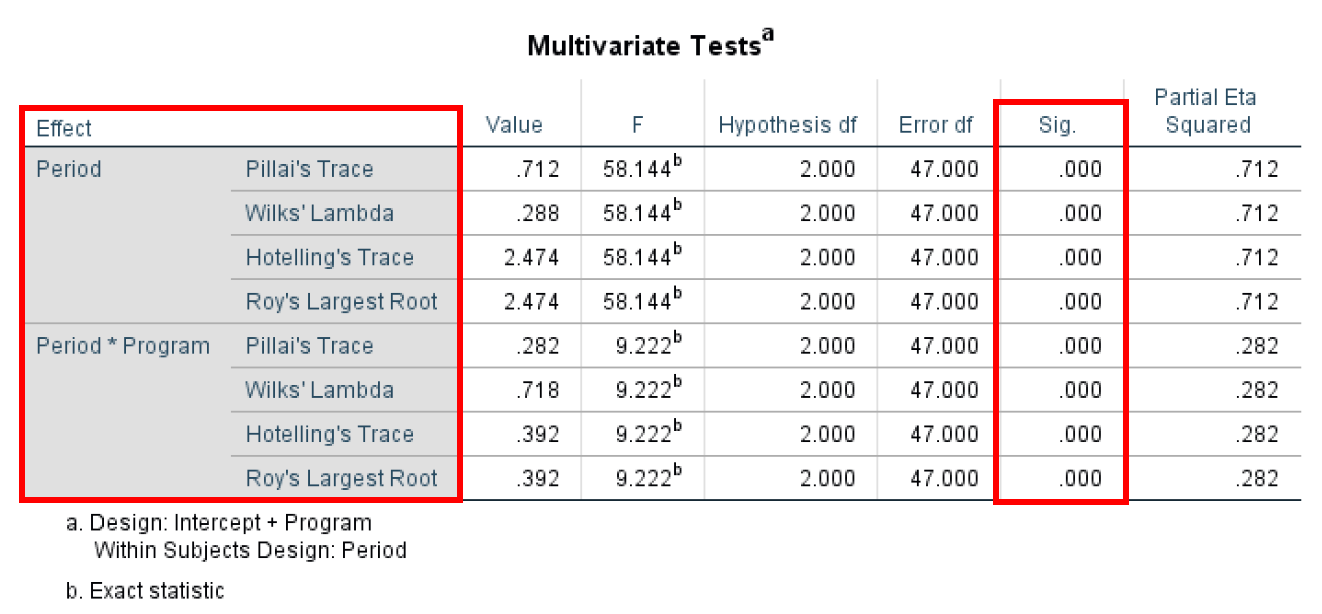 สถิติ Multivariate Test สำหรับ Repeated Measures ANOVA
สถิติ Multivariate Test สำหรับ Repeated Measures ANOVA
- Mauchly's Test of Sphericity ทดสอบว่าความแปรปรวนระหว่างความแตกต่างทั้งหมดระหว่างคู่ที่เป็นไปได้ทั้งหมดของกลุ่มเท่ากัน (ไม่ว่าสมมติฐาน Sphericity ถูกละเมิดหรือไม่)
Mauchly's Test มีระดับ α ที่ 0.05 และเพื่อให้เป็นไปตามสมมติฐาน Sphericity เราต้องมีค่ามากกว่านั้น ในกรณีของเรา P-value ที่คำนวณได้คือ 0.02 ดังนั้นเราจึงไม่เป็นไปตามสมมติฐาน Sphericity
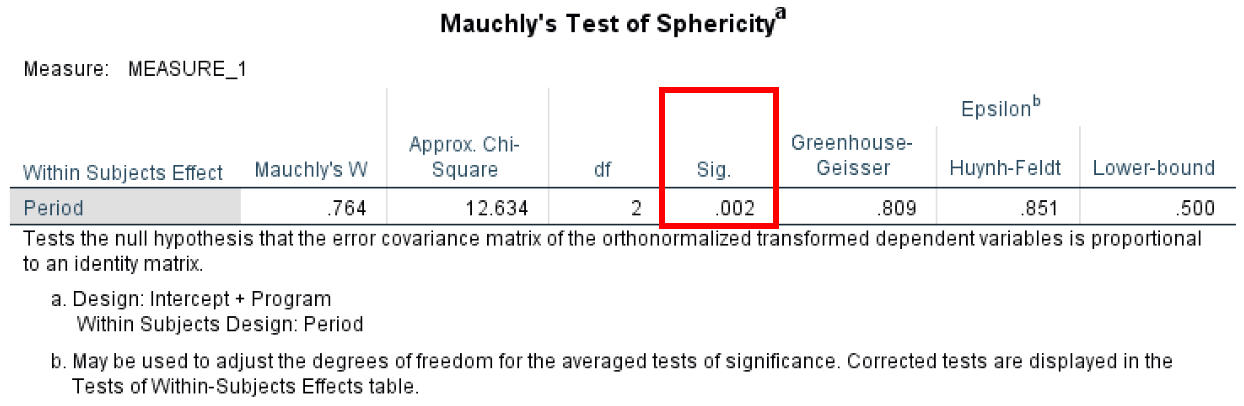 Mauchly's Test ตรวจสอบสมมติฐาน Sphericity สำหรับ Repeated Measures ANOVA
Mauchly's Test ตรวจสอบสมมติฐาน Sphericity สำหรับ Repeated Measures ANOVA
- Tests of Within-Subjects Effects ทดสอบว่ามีความแตกต่างที่มีนัยสำคัญระหว่างค่าเฉลี่ยในช่วงเวลาใดๆ หรือไม่ เช่นเดียวกับการทดสอบก่อนหน้านี้ Sphericity Assumed มีระดับ α ที่ 0.05 และ P-value < 0.05 แสดงนัยสำคัญทางสถิติ
ในกรณีของเรา เราสามารถสันนิษฐาน Sphericity สำหรับทั้ง Period และ Period*Program ได้
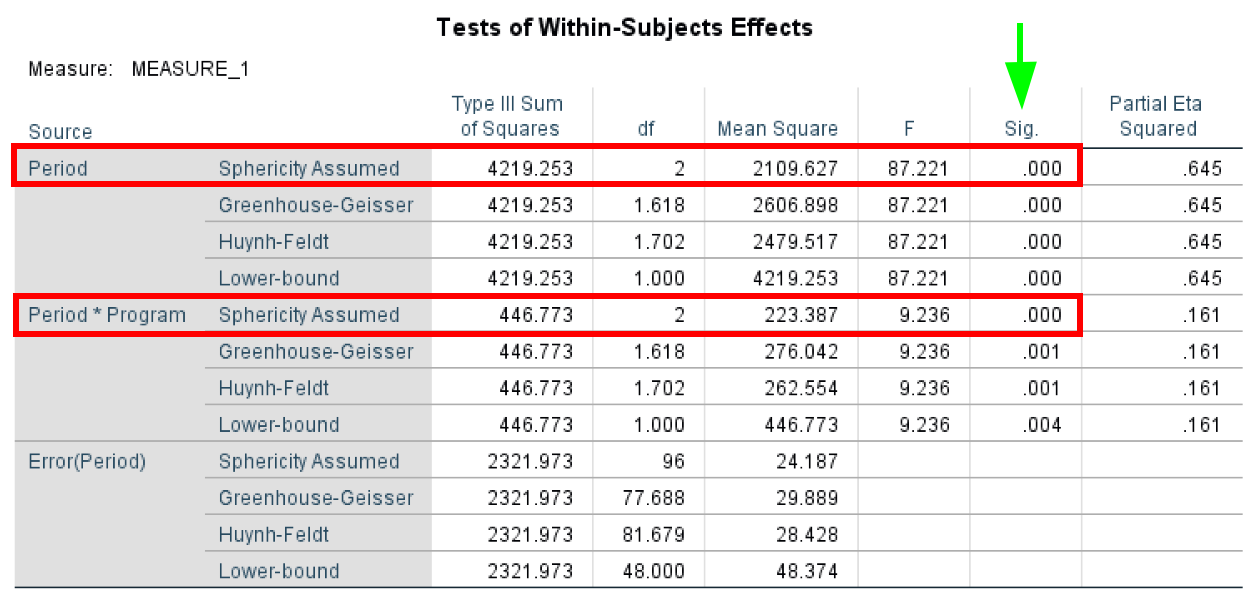 Within-Subjects Effects แสดงผลกระทบหลักที่มีนัยสำคัญของเวลา
Within-Subjects Effects แสดงผลกระทบหลักที่มีนัยสำคัญของเวลา
- Tests of Within-Subjects Contrasts ทดสอบว่ามีการเปลี่ยนแปลงที่มีนัยสำคัญทางสถิติระหว่างค่าเฉลี่ยในช่วงเวลาต่างๆ หรือไม่ และมีประโยชน์เมื่อทำ Trend Analysis Tests of Within-Subjects Contrasts มี α = 0.05 ในกรณีศึกษาของเรา เราสามารถเห็นได้ว่า Period และ Period*Program มีนัยสำคัญทางสถิติด้วย P-values < 0.05 ตามที่เน้นในตารางด้านล่าง
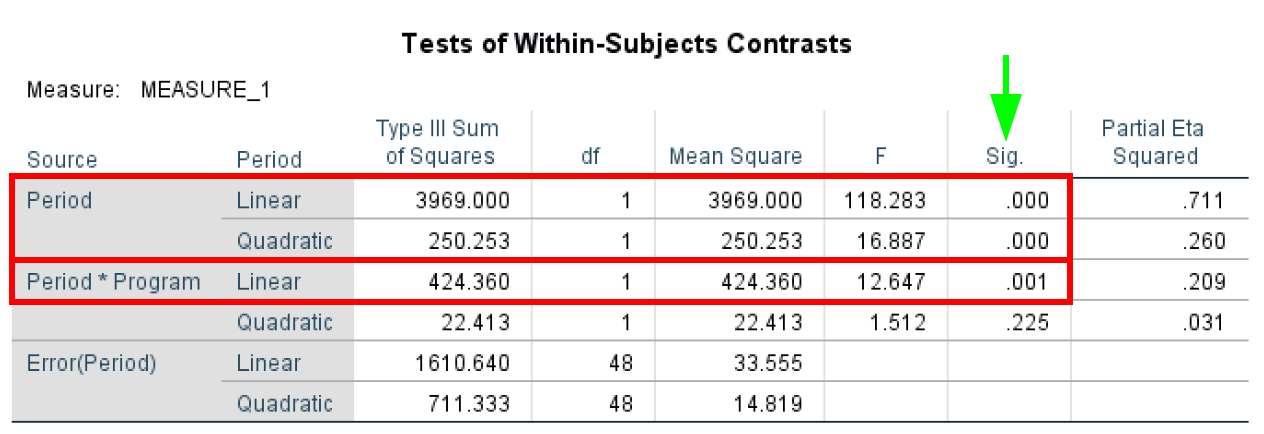 Within-Subjects Contrasts สำหรับ Trend Analysis
Within-Subjects Contrasts สำหรับ Trend Analysis
- Levene's Test of Equality of Error Variances ทดสอบความเป็นเนื้อเดียวกันของความแปรปรวนโดยเปรียบเทียบความแปรปรวนของสองกลุ่มหรือมากกว่าที่กำหนดตัวแปร Levene's Test of Equality of Error Variances มีระดับ α ที่ 0.05 โดยที่ P-value ใดๆ ต่ำกว่า 0.05 ละเมิดสมมติฐานความเป็นเนื้อเดียวกันของความแปรปรวน
เมื่อดูที่ผลลัพธ์ Levene's Test of Equality of Error Variance สำหรับกรณีศึกษาของเรา เราสามารถเห็นได้ว่า P-values ทั้งหมด >0.05 ดังนั้นเราจึงไม่ละเมิดสมมติฐานความเป็นเนื้อเดียวกันของความแปรปรวน
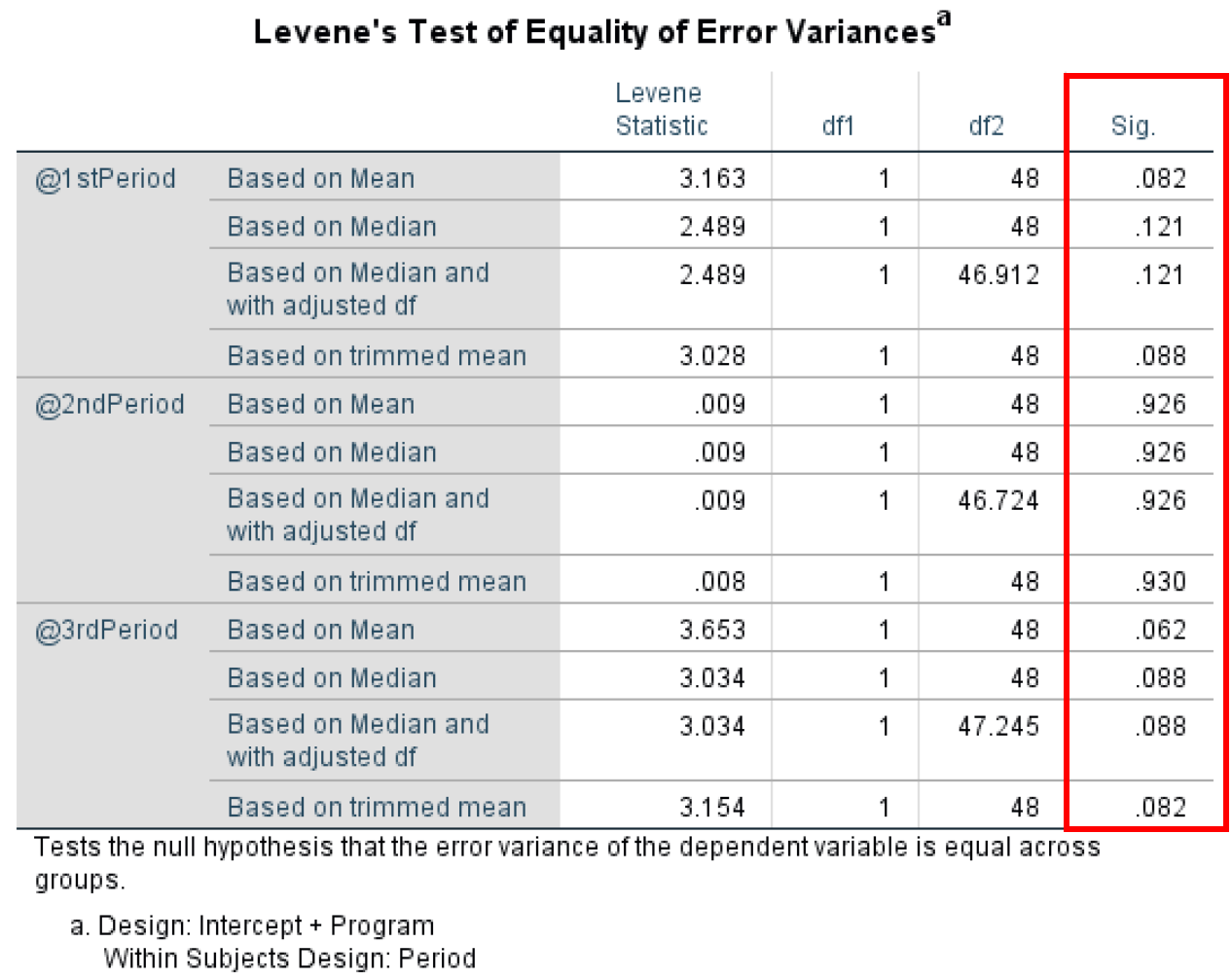 Levene's Test ยืนยันว่าสมมติฐาน Homogeneity of Variance เป็นไปตาม
Levene's Test ยืนยันว่าสมมติฐาน Homogeneity of Variance เป็นไปตาม
- Tests of Between-Subjects Effects ตรวจสอบความแตกต่างระหว่างผู้ตอบแบบสอบถาม Tests of Between-Subjects Effects มีระดับ α ที่ 0.05 ที่นี่เรากำลังดูที่ผลกระทบของตัวแปร Program ซึ่งแสดงไม่มีนัยสำคัญทางสถิติที่ P-value = 0.253 เนื่องจากเพียง 0.027 (Partial Eta Squared) ของความแปรปรวนในตัวแปรตามสามารถอธิบายได้โดยตัวแปร Program
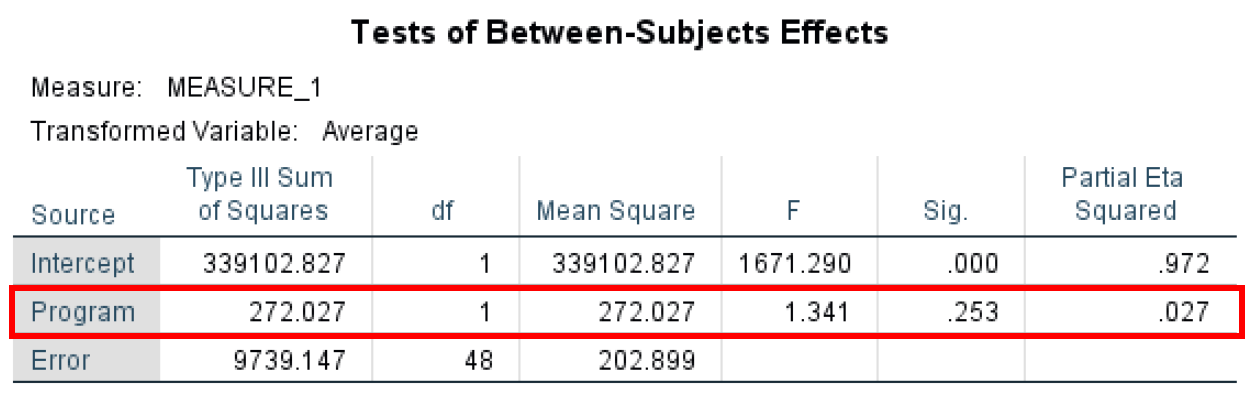 Between-Subjects Effects ทดสอบผลกระทบหลักของ Program
Between-Subjects Effects ทดสอบผลกระทบหลักของ Program
- ตาราง Estimated Margin Means แสดงให้เราเห็นสรุปการประมาณสำหรับค่าเฉลี่ยและ Standard Error สำหรับแต่ละช่วงเวลา ตลอดจนค่าขอบเขตล่างและบนที่ช่วงความเชื่อมั่น 95% คุณสามารถสังเกตได้ว่า Mean ในตาราง Estimates เป็นค่าเทียบเท่ากับ Total Mean ในตาราง Descriptive Statistics (3) จริงๆ
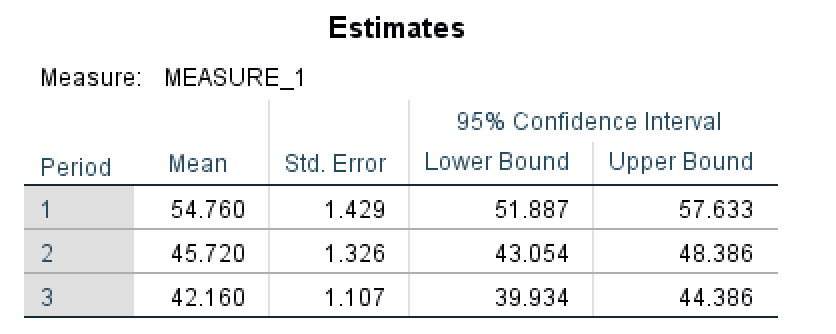 Estimated Marginal Means สำหรับแต่ละช่วงเวลาการวัด
Estimated Marginal Means สำหรับแต่ละช่วงเวลาการวัด
- Pairwise Comparison ทดสอบว่ามีความแตกต่างทางสถิติระหว่างคู่ใดๆ หรือไม่ – ในกรณีของเราคือสามช่วงเวลาของการศึกษา คุณสามารถเห็นได้ว่าเรามีนัยสำคัญทางสถิติระหว่างแต่ละคู่ (P-value < 0.05)
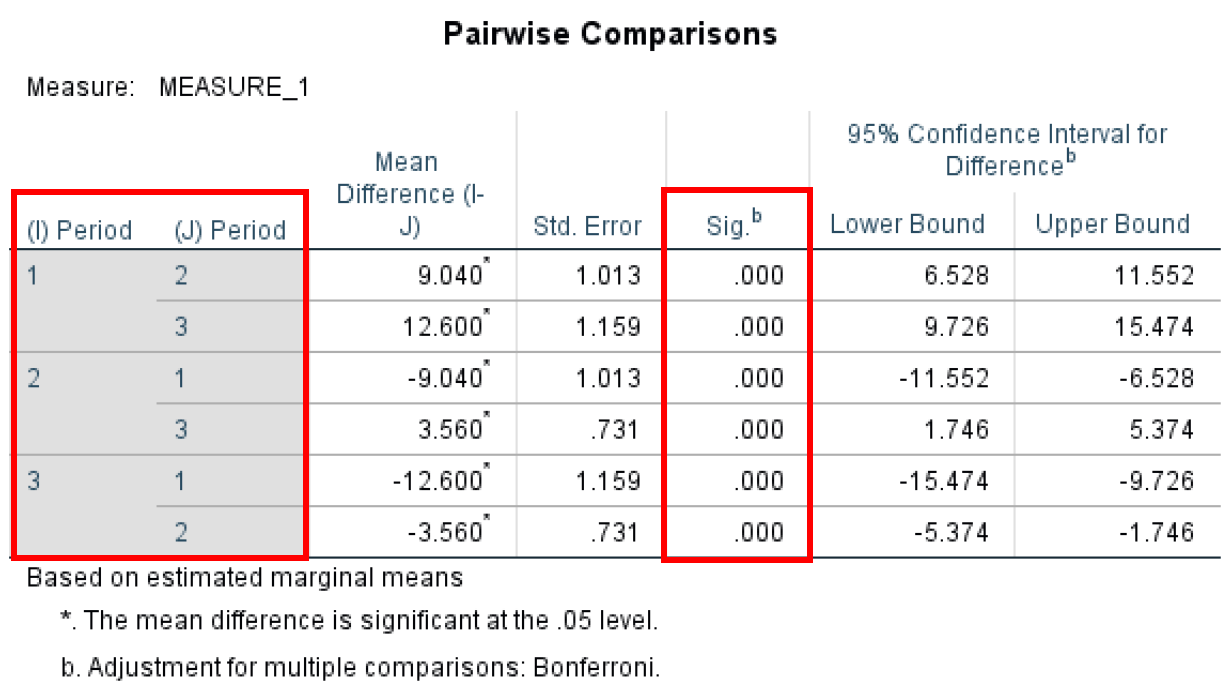 Pairwise Comparisons ที่แก้ไขด้วย Bonferroni ระหว่างช่วงเวลาทั้งหมด
Pairwise Comparisons ที่แก้ไขด้วย Bonferroni ระหว่างช่วงเวลาทั้งหมด
- สุดท้าย ตาราง Multivariate Test แสดงให้เราเห็นผลลัพธ์ที่คล้ายกับ Multivariate Test ที่เราพูดถึงก่อนหน้านี้ (5) และแสดงนัยสำคัญทางสถิติสำหรับสถิติการทดสอบที่แตกต่างกันทั้งหมดที่ใช้ในการวิเคราะห์ ANOVA สำหรับ Repeated Measures
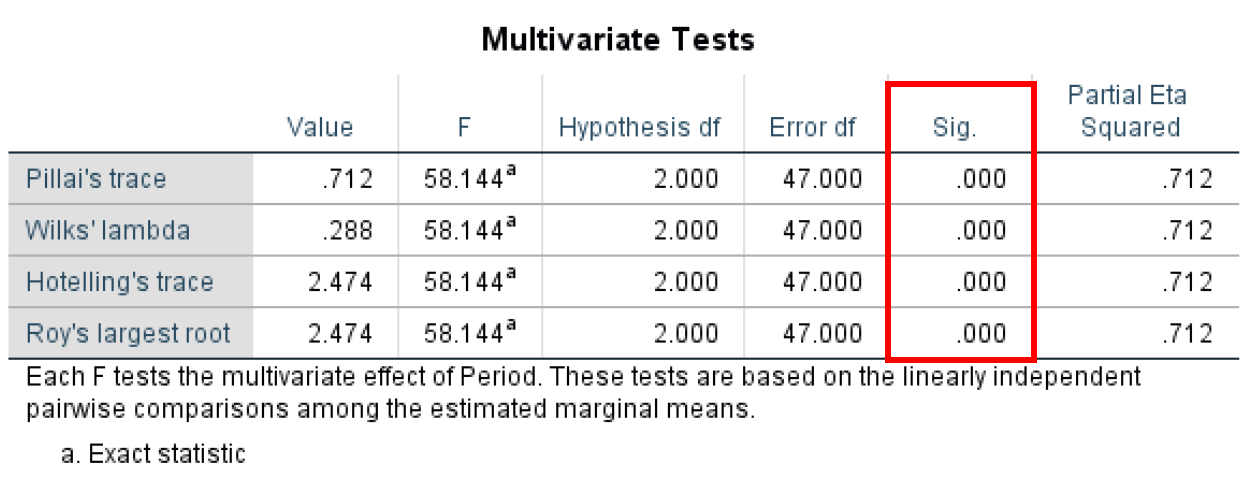 สถิติ Multivariate Test ยืนยันความแตกต่างที่มีนัยสำคัญในช่วงเวลา
สถิติ Multivariate Test ยืนยันความแตกต่างที่มีนัยสำคัญในช่วงเวลา
Repeated Measures ANOVA เทียบกับ One-Way ANOVA
นักวิจัยหลายคนสับสนระหว่าง Repeated Measures ANOVA กับ One-Way ANOVA แม้ว่าทั้งสองจะเป็นประเภทของ ANOVA แต่พวกเขาให้บริการการออกแบบการวิจัยที่แตกต่างกัน:
One-Way ANOVA (Between-Subjects):
- ผู้เข้าร่วมที่แตกต่างกันในแต่ละกลุ่ม
- ผู้เข้าร่วมแต่ละคนวัดครั้งเดียว
- ตัวอย่าง: เปรียบเทียบคะแนนทดสอบในวิธีการสอน 3 วิธีที่แตกต่างกันกับนักเรียน 3 กลุ่มแยกกัน
- สันนิษฐานความเป็นอิสระระหว่างกลุ่ม
One-Way Repeated Measures ANOVA (Within-Subjects):
- ผู้เข้าร่วมคนเดียวกันวัดหลายครั้ง
- ผู้เข้าร่วมแต่ละคนให้ข้อมูลสำหรับทุกเงื่อนไข/ช่วงเวลา
- ตัวอย่าง: วัดน้ำหนักของผู้เข้าร่วมคนเดียวกันใน 3 ช่วงเวลาที่แตกต่างกัน (พื้นฐาน, เดือน 1, เดือน 3)
- มีพลังทางสถิติมากกว่า (ควบคุมความแตกต่างระหว่างบุคคล)
- ต้องการสมมติฐาน Sphericity
เมื่อใดควรใช้แบบไหน:
- ใช้ One-Way ANOVA เมื่อคุณมีกลุ่มอิสระและผู้เข้าร่วมแต่ละคนเป็นของกลุ่มเดียวเท่านั้น
- ใช้ Repeated Measures ANOVA เมื่อคุณวัดผู้เข้าร่วมคนเดียวกันหลายครั้งหรือภายใต้เงื่อนไขที่แตกต่างกัน
- Repeated Measures ANOVA มีพลังมากกว่าเพราะมันคำนึงถึงความแปรปรวนของแต่ละบุคคล
วิธีการรายงานผลลัพธ์ Repeated Measures ANOVA
เมื่อรายงานผลลัพธ์ Repeated Measures ANOVA ของคุณในการเขียนทางวิชาการ ให้รวมองค์ประกอบหลักเหล่านี้:
ตัวอย่างรูปแบบ APA:
"ดำเนินการ One-Way Repeated Measures ANOVA เพื่อเปรียบเทียบคะแนนการลดน้ำหนักในสามช่วงเวลา: พื้นฐาน, 30 วัน และ 90 วัน Mauchly's Test แสดงว่าสมมติฐาน Sphericity ถูกละเมิด, χ²(2) = 7.89, p = .02, ดังนั้นจึงแก้ไข Degrees of Freedom โดยใช้ Greenhouse-Geisser Estimates of Sphericity (ε = 0.78).
ผลลัพธ์แสดงว่าเวลามีผลกระทบที่มีนัยสำคัญต่อการลดน้ำหนัก, F(1.56, 74.88) = 42.35, p < .001, partial η² = .47 Post Hoc Tests โดยใช้การแก้ไข Bonferroni เปิดเผยว่าการลดน้ำหนักแตกต่างกันอย่างมีนัยสำคัญระหว่างทั้งสามช่วงเวลา (ค่า p ทั้งหมด < .05)"
องค์ประกอบสำคัญที่ต้องรายงาน:
- การทดสอบที่ใช้: ระบุว่าคุณดำเนินการ One-Way Repeated Measures ANOVA
- ตัวแปร: ระบุ Within-Subjects Factor และระดับของคุณอย่างชัดเจน
- Sphericity: รายงานผลลัพธ์ Mauchly's Test และการแก้ไขใดๆ ที่ใช้ (Greenhouse-Geisser หรือ Huynh-Feldt)
- Main Effect: รายงาน F-statistic, Degrees of Freedom, p-value และขนาดผลกระทบ (Partial η²)
- Post Hoc Tests: ถ้ามีนัยสำคัญ รายงานว่าคู่ใดแตกต่างกัน (พร้อมวิธีการแก้ไขที่ใช้)
- Descriptive Statistics: รวมค่าเฉลี่ยและ Standard Deviations สำหรับแต่ละช่วงเวลา/เงื่อนไข
การตีความขนาดผลกระทบ (Partial η²):
- 0.01 = ผลกระทบขนาดเล็ก
- 0.06 = ผลกระทบขนาดกลาง
- 0.14 = ผลกระทบขนาดใหญ่
คำถามที่พบบ่อย
สรุป
นี่คือประเด็นสำคัญที่ต้องจำเกี่ยวกับ Repeated Measures ANOVA ใน SPSS:
-
ANOVA สำหรับ Repeated Measures มีประโยชน์เมื่อต้องการเปรียบเทียบค่าเฉลี่ยระหว่างสามกลุ่มขึ้นไปในการสังเกตที่แตกต่างกัน สำหรับการเปรียบเทียบค่าเฉลี่ยระหว่างสองกลุ่ม Sample T-Test ก็เพียงพอแล้ว
-
One-Way Repeated Measures ANOVA ใช้เมื่อการศึกษาการออกแบบ Repeated Measure ประกอบด้วยตัวแปรอิสระหนึ่งตัว ในขณะที่ Two-Way Repeated Measures ANOVA เราใช้ตัวทำนายสองตัว
-
เพื่อให้สามารถดำเนินการทดสอบ Repeated Measures ANOVA การออกแบบ Repeated Measure ของการศึกษาควรประกอบด้วยตัวแปรอิสระเชิงหมวดหมู่อย่างน้อยหนึ่งตัวและตัวแปรตามแบบต่อเนื่องหนึ่งตัว
บทความที่เกี่ยวข้อง:
หากคุณสนใจเรียนรู้เทคนิคการวิเคราะห์ทางสถิติอื่นๆ ใน SPSS ลองดูบทความเหล่านี้:
- การวิเคราะห์ Linear Regression ใน SPSS - เรียนรู้วิธีการวิเคราะห์ความสัมพันธ์เชิงเส้นระหว่างตัวแปร
- การวิเคราะห์ Mediation ใน SPSS - ค้นพบวิธีทดสอบตัวแปรคั่นกลางในโมเดลของคุณ
- การวิเคราะห์ Moderation ใน SPSS - เข้าใจวิธีทดสอบตัวแปรกำกับในการวิจัยของคุณ
เอกสารอ้างอิง
Cohen, J. (1988). Statistical power for the behavioral sciences (2nd edition). Lawrence Earlbaum: Hillsdale, NJ.
Field, A. (2018). Discovering statistics using IBM SPSS statistics (5th edition). Sage: Thousand Oaks, CA.
Pallant, J. (2010). SPSS survival manual: A step-by-step guide to data analysis using SPSS. Maidenhead: Open University Press/McGraw-Hill.
Pituch, K.A. and Stevens, J.P. (2016) Applied Multivariate Statistics for the Social Sciences.