การเรียนรู้วิธีการวิเคราะห์ตัวแปรคั่นกลางใน R เป็นสิ่งสำคัญสำหรับการทำความเข้าใจผลกระทบทางอ้อม (indirect effects) ในงานวิจัยของคุณ คู่มือฉบับสมบูรณ์นี้จะแสดงวิธีการทำ Mediation Analysis ใน R โดยใช้ lavaan package และเทคนิค R mediation พร้อมการสอนแบบทีละขั้นตอนโดยใช้ชุดข้อมูลตัวอย่างจำนวน 30 คน
ไม่ว่าคุณจะต้องการรัน mediation analysis R สำหรับวิทยานิพนธ์ ทำความเข้าใจ R mediation analysis เพื่อตีพิมพ์ผลงาน หรือสร้าง mediation model in R สำหรับงานวิจัยเชิงสำรวจ บทเรียนนี้ครอบคลุมทุกอย่าง เราจะแสดงวิธีการใช้ mediation package in R ด้วย lavaan การแปลผล path coefficients (a, b, c) และการสร้างภาพแบบมืออาชีพด้วยแผนภาพ
ใน 7 ขั้นตอนที่เข้าใจง่าย คุณจะเชี่ยวชาญ mediation R workflows โดยใช้ทั้ง lavaan และ mediation packages และเรียนรู้วิธีการทำ R mediation analysis แบบสมบูรณ์ตั้งแต่การนำเข้าข้อมูลจนถึงการแปลผล
สิ่งที่คุณจะได้เรียนรู้
เมื่อจบบทเรียนนี้ คุณจะสามารถ:
-
เข้าใจแนวคิดของการวิเคราะห์ตัวแปรคั่นกลางและจุดประสงค์ในการสำรวจผลกระทบทางอ้อม
-
สร้างภาพแผนภาพ mediation model ด้วยแผนภาพง่ายๆ
-
ติดตั้งและโหลด R packages ที่จำเป็นสำหรับการวิเคราะห์ตัวแปรคั่นกลาง
-
นำเข้าและสำรวจชุดข้อมูลใน R โดยคำนวณสถิติเชิงพรรณนาและความสัมพันธ์ระหว่างตัวแปร
-
กำหนด mediation model ใน R
-
ประมาณค่าและปรับ mediation model เข้ากับชุดข้อมูลของคุณใน R
-
แปลผลการวิเคราะห์ตัวแปรคั่นกลาง รวมถึง direct effects, indirect effects และ total effects
-
สร้างภาพแสดงผลการวิเคราะห์ตัวแปรคั่นกลางใน R
-
ประยุกต์ใช้กระบวนการวิเคราะห์ตัวแปรคั่นกลางกับคำถามวิจัยและชุดข้อมูลของคุณเอง
พร้อมแล้วหรือยัง? มาเริ่มต้นและสำรวจกระบวนการกันเลย!
Mediation Analysis คืออะไร?
ก่อนที่เราจะเริ่มวิเคราะห์ตัวเลข มาทำความเข้าใจกันก่อนว่าการวิเคราะห์ตัวแปรคั่นกลางคืออะไร นี่เป็นเทคนิคทางสถิติที่ช่วยให้เราเข้าใจว่าตัวแปรอิสระ (Independent Variable - X) มีอิทธิพลต่อตัวแปรตาม (Dependent Variable - Y) อย่างไรผ่านทางตัวแปรคั่นกลาง (Mediator Variable - M)
 แผนภาพ mediation model พื้นฐานแสดงเส้นทาง X→M→Y
แผนภาพ mediation model พื้นฐานแสดงเส้นทาง X→M→Y
Mediation Analysis มีประโยชน์อย่างยิ่งในการกำหนดว่าผลกระทบของ X ต่อ Y นั้นถูกคั่นกลางโดย M แบบสมบูรณ์ บางส่วน หรือไม่มีการคั่นกลางเลย
ชุดข้อมูลของเรา: ภาพรวมโดยสังเขป
ในตัวอย่างของเรา เราจะทำงานกับชุดข้อมูลของผู้ตอบแบบสอบถาม 30 คน สมมติว่าผู้ตอบแบบสอบถามเหล่านี้เป็นพนักงาน และเราต้องการศึกษาความสัมพันธ์ระหว่างความพึงพอใจในงาน (job satisfaction - X), ผลการปฏิบัติงาน (job performance - Y) และแรงจูงใจในสถานที่ทำงาน (workplace motivation - M)
เราตั้งสมมติฐานว่าความพึงพอใจในงานมีอิทธิพลต่อผลการปฏิบัติงานโดยอ้อมผ่านทางแรงจูงใจในสถานที่ทำงาน ดังนั้น เราจะทำการวิเคราะห์ตัวแปรคั่นกลางเพื่อดูว่าสิ่งนี้เป็นจริงหรือไม่
เพื่อสร้างภาพสมมติฐานของเรา เราสามารถสร้างแผนภาพง่ายๆ ที่มีตัวแปรสามตัว: ความพึงพอใจในงาน (X), แรงจูงใจในสถานที่ทำงาน (M) และผลการปฏิบัติงาน (Y)
 ตัวอย่าง Mediation model: job satisfaction → workplace motivation → job performance
ตัวอย่าง Mediation model: job satisfaction → workplace motivation → job performance
ในแผนภาพนี้ ลูกศรจาก X ไปยัง M แสดงถึงผลกระทบของความพึงพอใจในงานต่อแรงจูงใจในสถานที่ทำงาน (a path) ลูกศรจาก M ไปยัง Y แสดงถึงผลกระทบของแรงจูงใจในสถานที่ทำงานต่อผลการปฏิบัติงาน (b path) ผลกระทบทางอ้อมของความพึงพอใจในงานต่อผลการปฏิบัติงานผ่านทางแรงจูงใจในสถานที่ทำงานคือผลคูณของ a และ b paths (a * b)
วิธีการวิเคราะห์ตัวแปรคั่นกลางใน R
ตอนนี้เราได้มีความเข้าใจที่ชัดเจนเกี่ยวกับชุดข้อมูลและสมมติฐานของเราแล้ว มาเริ่มใช้งาน R และทำงานกับข้อมูลกันเลย
ขั้นตอนที่ 1: ติดตั้งและโหลด Packages
ก่อนอื่น เราจะต้องติดตั้งและโหลด packages ที่จำเป็นสำหรับการทำ mediation analysis ใน R รวมถึงการสร้างภาพผลลัพธ์:
# Install packages
install.packages("psych")
install.packages("lavaan")
install.packages("ggplot2")
install.packages("readxl")
install.packages("semPlot")
# Load packages
library(psych)
library(lavaan)
library(ggplot2)
library(readxl)
library(semPlot)
นี่คือคำอธิบายโดยย่อของ packages ข้างต้น:
-psych: Package สำหรับการวิเคราะห์ทางจิตวิทยาและการวัดทางจิตมิติ เช่น factor analysis และสถิติเชิงพรรณนา
-lavaan: Package สำหรับการสร้างแบบจำลองสมการโครงสร้าง (Structural Equation Modeling - SEM) ด้วย syntax ที่เป็นมิตรกับผู้ใช้และดัชนีความพอดีหลายแบบ
-ggplot2: Package สร้างภาพข้อมูลที่ยืดหยุ่นอิงตาม Grammar of Graphics สำหรับสร้างกราฟที่ซับซ้อนและปรับแต่งได้
-readxl: Package น้ำหนักเบาสำหรับการนำเข้าไฟล์ Excel (.xls และ .xlsx) เข้าสู่ data frames ใน R
-semPlot: เครื่องมือสร้างภาพสำหรับสร้าง path diagrams ของแบบจำลองสมการโครงสร้าง (SEMs) พร้อมตัวเลือกการปรับแต่ง
ขั้นตอนที่ 2: นำเข้าและสำรวจชุดข้อมูล
ต่อไป เราจะนำเข้าชุดข้อมูลของเราเข้าสู่ R และดูแถวแรกๆ เพื่อทำความคุ้นเคยกับข้อมูล คุณอาจใช้ชุดข้อมูลของคุณเอง หรือดาวน์โหลดชุดข้อมูลฝึกหัดจากแถบด้านข้าง (เพื่อการศึกษาเท่านั้น)
หมายเหตุ: หากชุดข้อมูลของคุณเป็นไฟล์ Excel .xlsx ให้ใช้ syntax ดังนี้:
# Import the dataset
data <- read_excel("path/to/your/dataset.xlsx")
#Explore dataset
head(data)
- หากชุดข้อมูลของคุณเป็นไฟล์ Excel .csv ให้ใช้ syntax ดังนี้:
# Import dataset
data <- read.csv("path/to/your/dataset.csv")
# Explore dataset
head(data)
สมมติว่าชุดข้อมูลของเราประกอบด้วยสามคอลัมน์ – job_satisfaction, workplace_motivation และ job_performance – ผลลัพธ์ควรมีลักษณะประมาณนี้:
 ตัวอย่างชุดข้อมูลแสดง 6 แถวแรกของชุดข้อมูลการวิเคราะห์ตัวแปรคั่นกลางใน R
ตัวอย่างชุดข้อมูลแสดง 6 แถวแรกของชุดข้อมูลการวิเคราะห์ตัวแปรคั่นกลางใน R
ขั้นตอนที่ 3: สถิติเชิงพรรณนาและความสัมพันธ์
ก่อนที่เราจะรันการวิเคราะห์ตัวแปรคั่นกลาง มาคำนวณสถิติเชิงพรรณนาและความสัมพันธ์สำหรับตัวแปรของเรากันก่อน
# Descriptive statistics
summary(data)
# Correlations
correlations <- cor(data)
print(correlations)
สิ่งนี้จะให้ภาพรวมของค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน และความสัมพันธ์ของตัวแปรของเรา
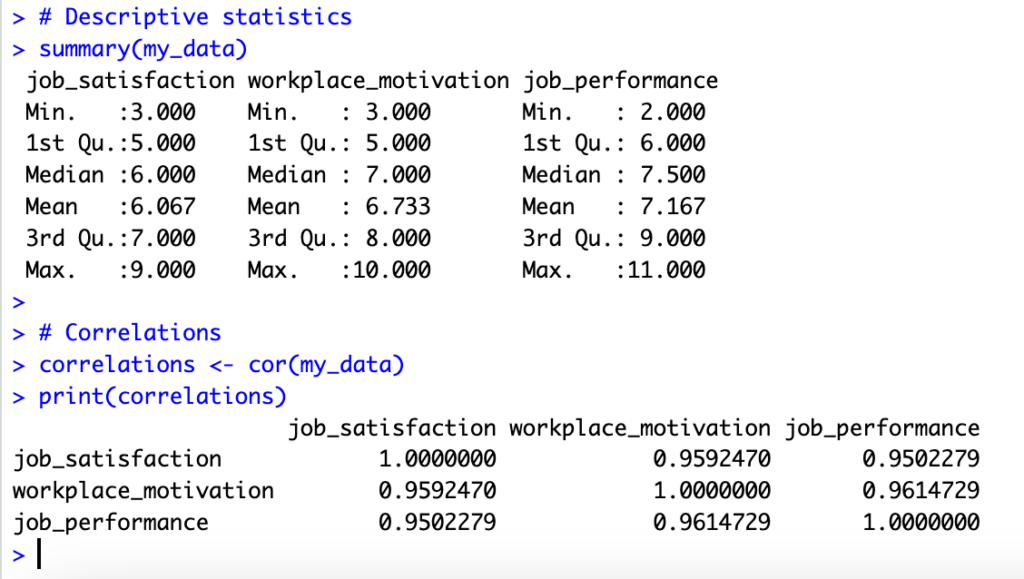 ผลลัพธ์สถิติเชิงพรรณนาและ correlation matrix ใน R สำหรับตัวแปร mediation
ผลลัพธ์สถิติเชิงพรรณนาและ correlation matrix ใน R สำหรับตัวแปร mediation
การทำสถิติเชิงพรรณนาและการวิเคราะห์ความสัมพันธ์ก่อนการวิเคราะห์ตัวแปรคั่นกลางเป็นสิ่งสำคัญด้วยเหตุผลหลายประการ:
-การทำความเข้าใจข้อมูล: สถิติเชิงพรรณนาให้สรุปชุดข้อมูลของคุณและช่วยให้คุณเข้าใจแนวโน้มเข้าสู่ส่วนกลาง การกระจาย และรูปร่างของการแจกแจงสำหรับแต่ละตัวแปร ความเข้าใจนี้มีความสำคัญก่อนที่จะดำเนินการวิเคราะห์ที่ซับซ้อนกว่า เช่น mediation analysis เพราะจะช่วยให้คุณระบุปัญหาหรือค่าผิดปกติในข้อมูลได้
-การตรวจสอบข้อสมมติฐาน: เทคนิคทางสถิติหลายแบบ รวมถึง mediation analysis อาศัยข้อสมมติฐานบางประการเกี่ยวกับข้อมูล สถิติเชิงพรรณนาสามารถช่วยคุณประเมินว่าข้อสมมติฐานเหล่านี้ได้รับการปฏิบัติตามหรือไม่ ตัวอย่างเช่น การแจกแจงแบบปกติของตัวแปรมักเป็นข้อสมมติฐานใน mediation analysis และคุณสามารถตรวจสอบสิ่งนี้ผ่านสถิติเชิงพรรณนา เช่น skewness และ kurtosis
-ข้อมูลเชิงลึกเบื้องต้น: การวิเคราะห์ความสัมพันธ์ให้ความเข้าใจเบื้องต้นเกี่ยวกับความสัมพันธ์ระหว่างตัวแปรของคุณ มันช่วยให้คุณตรวจสอบความแข็งแกร่งและทิศทางของความสัมพันธ์ ซึ่งอาจเป็นประโยชน์ในการสร้างสมมติฐานหรือการกำหนด mediation model ความสัมพันธ์ที่แข็งแกร่งระหว่างตัวแปรอิสระ (X) และตัวแปรคั่นกลาง (M) รวมถึงระหว่างตัวแปรคั่นกลาง (M) และตัวแปรตาม (Y) อาจบ่งบอกถึงการมีอยู่ของ mediation effects
-การประเมิน Multicollinearity: การตรวจสอบความสัมพันธ์ยังสามารถช่วยคุณตรวจจับ multicollinearity ซึ่งเป็นสถานการณ์ที่ตัวแปรพยากรณ์สองตัวขึ้นไปมีความสัมพันธ์กันสูง Multicollinearity สามารถสร้างปัญหาใน mediation analysis เพราะอาจนำไปสู่การประมาณค่าที่ไม่เสถียรหรือ standard errors ที่สูงเกินจริง โดยการระบุ multicollinearity ตั้งแต่เนิ่นๆ คุณสามารถจัดการกับมันก่อนดำเนินการวิเคราะห์ตัวแปรคั่นกลาง
ขั้นตอนที่ 4: กำหนด Mediation Model
ตอนนี้เราเข้าใจชุดข้อมูลของเราแล้ว ได้เวลากำหนด mediation model เราจะใช้ R lavaan package เพื่อกำหนดโมเดลโดยใช้ syntax ดังนี้:
mediation_model <- '
# Direct effects
workplace_motivation ~ a*job_satisfaction
job_performance ~ c * job_satisfaction + b*workplace_motivation
# Indirect effect (a * b)
indirect := a*b
# Total effect (c + indirect)
total := c + indirect
'
ในโมเดลนี้ เรากำหนดผลกระทบโดยตรง (direct effects) ของ job satisfaction (X) ต่อ workplace motivation (M) และ job performance (Y) เรายังกำหนด indirect effect (a*b) และ total effect (c + indirect)
หมายเหตุ: หากคุณสงสัยว่าทำไมคุณไม่ได้รับผลลัพธ์ใดๆ จากสคริปต์ R ข้างต้น เป็นเพราะสิ่งนี้เพียงแค่กำหนด mediation model เป็นสตริงแต่ไม่ได้ทำการวิเคราะห์หรือพิมพ์ผลลัพธ์ใดๆ การวิเคราะห์ตัวแปรคั่นกลางที่แท้จริงใน R จะถูกทำในขั้นตอนถัดไป
ขั้นตอนที่ 5: ประมาณค่า Mediation Model
เมื่อเรากำหนด mediation model แล้ว ตอนนี้เราสามารถประมาณค่ามันโดยใช้ lavaan package เราจะปรับโมเดลให้เข้ากับชุดข้อมูลของเราแล้วสรุปผลลัพธ์
# Estimate the mediation model
mediation_results <- sem(mediation_model, data = data)
# Summarize the results
summary(mediation_results, standardized = TRUE, fit.measures = TRUE)
ผลสรุปจะแสดง direct effects ที่ประมาณค่าได้ (a, b และ c paths), indirect effect (a*b) และ total effect (c + indirect) พร้อมกับระดับนัยสำคัญ – ดังที่เห็นด้านล่าง:
 Lavaan SEM output แสดงผลการวิเคราะห์ตัวแปรคั่นกลางพร้อม path estimates และระดับนัยสำคัญ
Lavaan SEM output แสดงผลการวิเคราะห์ตัวแปรคั่นกลางพร้อม path estimates และระดับนัยสำคัญ
เอาล่ะ แต่ตัวเลขทั้งหมดเหล่านี้หมายความว่าอย่างไร? มาคุยกันในหัวข้อถัดไป
ขั้นตอนที่ 6: การอ่านค่า / การแปลผล Mediation Output ใน R
จากผลลัพธ์ของการวิเคราะห์ตัวแปรคั่นกลางของคุณโดยใช้ชุดข้อมูลตัวอย่างที่เราใช้ในบทเรียนนี้ นี่คือวิธีการแปลผลการวิเคราะห์ตัวแปรคั่นกลางใน R:
Parameter Estimates:
-
Path a (job satisfaction -> workplace motivation): ค่าสัมประสิทธิ์ที่ประมาณการได้สำหรับผลกระทบโดยตรงของ job satisfaction (X) ต่อ workplace motivation (M) คือ 1.218 สิ่งนี้แสดงให้เห็นว่าโดยเฉลี่ย การเพิ่มขึ้น 1 หน่วยของความพึงพอใจในงานมีความสัมพันธ์กับการเพิ่มขึ้น 1.218 หน่วยของแรงจูงใจในสถานที่ทำงาน สมมติว่ามีความสัมพันธ์เชิงเส้น (linear relationship) ค่าสัมประสิทธิ์มาตรฐาน (Std.all) คือ 1.000 ซึ่งบ่งบอกถึงความสัมพันธ์เชิงบวกที่แข็งแกร่งระหว่างความพึงพอใจในงานและแรงจูงใจในสถานที่ทำงาน
-
Path b (workplace motivation -> job performance): ค่าสัมประสิทธิ์ที่ประมาณการได้สำหรับผลกระทบโดยตรงของ workplace motivation (M) ต่อ job performance (Y) คือ 0.727 สิ่งนี้แสดงให้เห็นว่าโดยเฉลี่ย การเพิ่มขึ้น 1 หน่วยของแรงจูงใจในสถานที่ทำงานมีความสัมพันธ์กับการเพิ่มขึ้น 0.727 หน่วยของผลการปฏิบัติงาน สมมติว่ามีความสัมพันธ์เชิงเส้น ค่าสัมประสิทธิ์มาตรฐาน (Std.all) คือ 0.632 ซึ่งบ่งบอกถึงความสัมพันธ์เชิงบวกในระดับปานกลางระหว่างแรงจูงใจในสถานที่ทำงานและผลการปฏิบัติงาน
-
Path c (job satisfaction -> job performance): ค่าสัมประสิทธิ์ที่ประมาณการได้สำหรับผลกระทบโดยตรงของ job satisfaction (X) ต่อ job performance (Y) โดยไม่พิจารณาผลกระทบของการคั่นกลางคือ 0.516 สิ่งนี้แสดงให้เห็นว่าโดยเฉลี่ย การเพิ่มขึ้น 1 หน่วยของความพึงพอใจในงานมีความสัมพันธ์กับการเพิ่มขึ้น 0.516 หน่วยของผลการปฏิบัติงาน สมมติว่ามีความสัมพันธ์เชิงเส้น ค่าสัมประสิทธิ์มาตรฐาน (Std.all) คือ 0.368 ซึ่งบ่งบอกถึงความสัมพันธ์เชิงบวกในระดับอ่อนถึงปานกลางระหว่างความพึงพอใจในงานและผลการปฏิบัติงาน
Defined Parameters:
-
Indirect effect (a*b): ผลกระทบทางอ้อมที่ประมาณการได้ของ job satisfaction (X) ต่อ job performance (Y) ผ่านทาง workplace motivation (M) คือ 0.885 สิ่งนี้แสดงให้เห็นว่าโดยเฉลี่ย การเพิ่มขึ้น 1 หน่วยของความพึงพอใจในงานส่งผลให้เกิดการเพิ่มขึ้น 0.885 หน่วยของผลการปฏิบัติงานโดยอ้อมผ่านทางผลกระทบต่อแรงจูงใจในสถานที่ทำงาน ผลกระทบทางอ้อมที่เป็นมาตรฐาน (Std.all) คือ 0.632 ซึ่งบ่งบอกถึงความสัมพันธ์เชิงบวกในระดับปานกลาง
-
Total effect (c + indirect): ผลกระทบรวมที่ประมาณการได้ของ job satisfaction (X) ต่อ job performance (Y) โดยพิจารณาทั้งผลกระทบโดยตรงและทางอ้อมคือ 1.401 สิ่งนี้แสดงให้เห็นว่าโดยเฉลี่ย การเพิ่มขึ้น 1 หน่วยของความพึงพอใจในงานมีความสัมพันธ์กับการเพิ่มขึ้น 1.401 หน่วยของผลการปฏิบัติงานเมื่อพิจารณาทั้งผลกระทบโดยตรงและทางอ้อม ผลกระทบรวมที่เป็นมาตรฐาน (Std.all) คือ 1.000 ซึ่งบ่งบอกถึงความสัมพันธ์เชิงบวกที่แข็งแกร่ง
ขอให้ทราบว่าผลลัพธ์ที่นำเสนอที่นี่อิงจาก ชุดข้อมูลสมมติที่สร้างขึ้นเพื่อการสาธิตเท่านั้น และการแปลผลไม่ควรถือว่ามีความหมาย อย่างไรก็ตาม กระบวนการแปลผลการวิเคราะห์ตัวแปรคั่นกลางยังคงเหมือนเดิมสำหรับชุดข้อมูลในชีวิตจริง
ขั้นตอนที่ 7: สร้างภาพ Mediation ใน R
เพื่อให้ผลลัพธ์ของเราเข้าถึงได้มากขึ้น มาสร้างแผนภาพโดยใช้ package ggplot2:
# Load the necessary libraries
library(ggplot2)
# Create a bar plot to visualize the path coefficients
ggplot(path_data, aes(x = path, y = coefficient, fill = path)) +
geom_bar(stat = "identity", position = position_dodge()) +
geom_text(aes(label = round(coefficient, 3)), vjust = -0.3, size = 4) +
theme_minimal() +
theme(legend.position = "none") +
ylab("Coefficient") +
xlab("Path") +
ggtitle("Mediation Analysis Results")
สคริปต์ข้างต้นจะสร้างแผนภูมิแท่งที่แสดงค่าสัมประสิทธิ์สำหรับแต่ละ path ใน mediation model ของเรา:
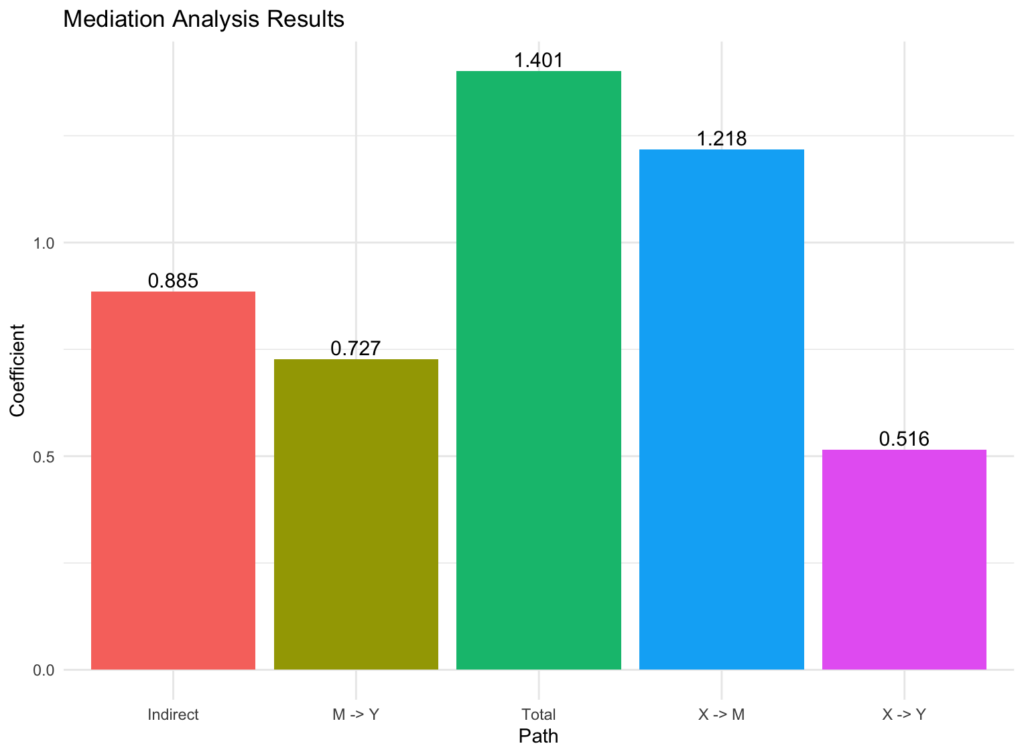 Bar chart แสดง path coefficients (a, b, c, indirect, total) จากการวิเคราะห์ตัวแปรคั่นกลาง
Bar chart แสดง path coefficients (a, b, c, indirect, total) จากการวิเคราะห์ตัวแปรคั่นกลาง
แผนภูมิแท่งที่เราสร้างข้างต้นเป็นการแสดงที่ดีของการวิเคราะห์ตัวแปรคั่นกลางของเรา แต่เราสามารถผลักดันสิ่งนี้ให้ไกลยิ่งขึ้นและสร้างแผนภาพ mediation พร้อมการประมาณค่า path ที่แสดงบนลูกศร ทำให้ง่ายต่อการแปลผลความสัมพันธ์ระหว่างตัวแปรโดยใช้สคริปต์ R ดังนี้:
# Load the necessary libraries
library(ggplot2)
library(semPlot)
# Create a bar plot to visualize the path coefficients
bar_plot <- ggplot(path_data, aes(x = path, y = coefficient, fill = path)) +
geom_bar(stat = "identity", position = position_dodge()) +
geom_text(aes(label = round(coefficient, 3)), vjust = -0.3, size = 4) +
theme_minimal() +
theme(legend.position = "none") +
ylab("Coefficient") +
xlab("Path") +
ggtitle("Mediation Analysis Results")
# Plot the bar plot
print(bar_plot)
# Plot the mediation diagram with path estimates
semPaths(mediation_fit, whatLabels = "est", style = "lisrel", intercepts = FALSE)
สิ่งนี้จะสร้างแผนภาพ mediation พร้อมการประมาณค่า path ที่แสดงบนลูกศร ทำให้ง่ายต่อการแปลผลความสัมพันธ์ระหว่างตัวแปรในโมเดลของเรา:
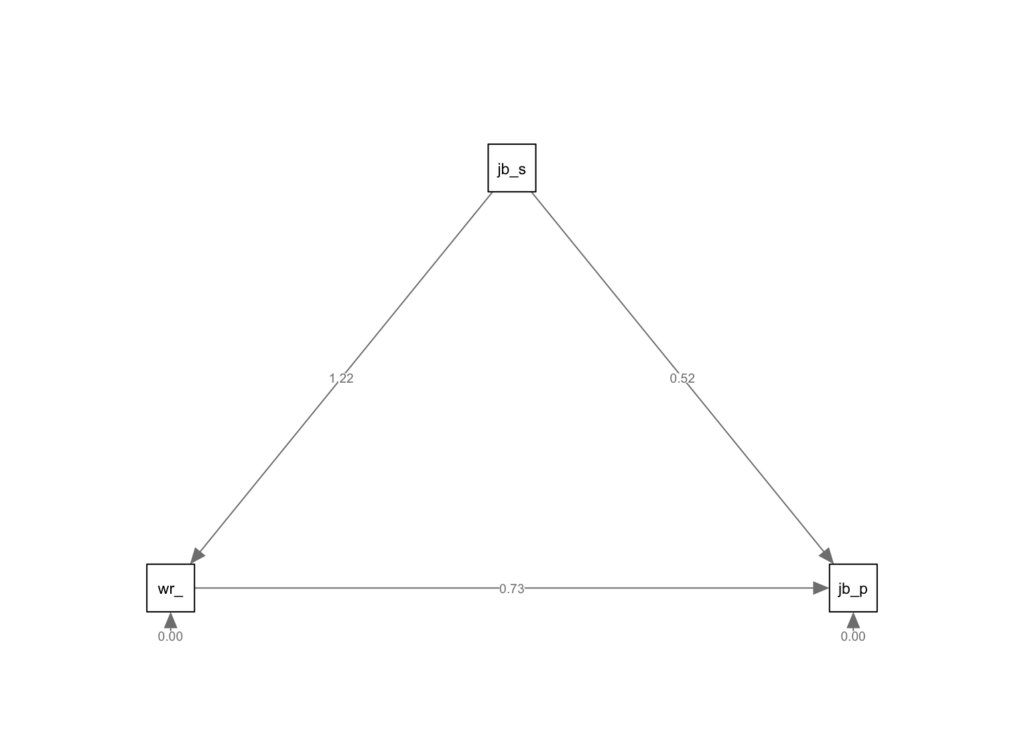 Path diagram ที่สร้างด้วย semPlot แสดง mediation model พร้อมค่าสัมประสิทธิ์ที่ประมาณการได้
Path diagram ที่สร้างด้วย semPlot แสดง mediation model พร้อมค่าสัมประสิทธิ์ที่ประมาณการได้
นี่คือคำอธิบายโดยย่อเกี่ยวกับวิธีการแปลผลแผนภาพข้างต้น:
-X -> M (a path): ลูกศรนี้แสดงผลกระทบของ job satisfaction (X) ต่อ workplace motivation (M) ตัวเลขบวกหมายความว่าเมื่อความพึงพอใจในงานเพิ่มขึ้น แรงจูงใจในสถานที่ทำงานก็เพิ่มขึ้นด้วย ตัวเลขลบบ่งบอกว่าเมื่อความพึงพอใจในงานเพิ่มขึ้น แรงจูงใจในสถานที่ทำงานจะลดลง ขนาดของตัวเลขสะท้อนถึงความแข็งแกร่งของความสัมพันธ์นี้
-M -> Y (b path): ลูกศรนี้แสดงถึงผลกระทบของ workplace motivation (M) ต่อ job performance (Y) สมมติว่า job satisfaction (X) ถูกควบคุมให้คงที่ ตัวเลขบวกหมายความว่าเมื่อแรงจูงใจในสถานที่ทำงานเพิ่มขึ้น ผลการปฏิบัติงานก็เพิ่มขึ้นด้วย ตัวเลขลบบ่งบอกว่าเมื่อแรงจูงใจในสถานที่ทำงานเพิ่มขึ้น ผลการปฏิบัติงานจะลดลง ขนาดของตัวเลขสะท้อนถึงความแข็งแกร่งของความสัมพันธ์นี้
-X -> Y (c path): ลูกศรนี้แสดงผลกระทบโดยตรงของ job satisfaction (X) ต่อ job performance (Y) โดยไม่พิจารณาตัวแปรคั่นกลาง (workplace motivation) ตัวเลขบวกหมายความว่าเมื่อความพึงพอใจในงานเพิ่มขึ้น ผลการปฏิบัติงานก็เพิ่มขึ้นด้วย ตัวเลขลบบ่งบอกว่าเมื่อความพึงพอใจในงานเพิ่มขึ้น ผลการปฏิบัติงานจะลดลง ขนาดของตัวเลขสะท้อนถึงความแข็งแกร่งของความสัมพันธ์นี้
ในการแปลผลผลลัพธ์ ให้พิจารณาเครื่องหมาย (บวกหรือลบ) และขนาดของ path coefficients ค่าสัมบูรณ์ที่ใหญ่กว่าบ่งบอกถึงความสัมพันธ์ที่แข็งแกร่งกว่าระหว่างตัวแปร
หาก indirect effect (a* b) มีนัยสำคัญ จะแสดงให้เห็นว่า workplace motivation เป็นตัวแปรคั่นกลางในความสัมพันธ์ระหว่าง job satisfaction และ job performance ในกรณีนี้ ส่วนหนึ่งของผลกระทบของความพึงพอใจในงานต่อผลการปฏิบัติงานสามารถอธิบายได้ผ่านทางแรงจูงใจในสถานที่ทำงาน
คำถามที่พบบ่อย
สรุป
ในคู่มือที่ครอบคลุมนี้ คุณได้เรียนรู้ วิธีการวิเคราะห์ตัวแปรคั่นกลางใน R โดยใช้ lavaan package ด้วยกระบวนการ 7 ขั้นตอนที่สมบูรณ์ ตั้งแต่การติดตั้ง packages ไปจนถึงการสร้างภาพผลลัพธ์ ตอนนี้คุณเข้าใจวิธีการทำ mediation in R การแปลผล path coefficients (a, b, c) และการทดสอบ indirect effects แล้ว
mediation analysis R workflow ที่เราครอบคลุม—ตั้งแต่การนำเข้าข้อมูลผ่านการแปลผล R mediation analysis—ให้พื้นฐานที่มั่นคงสำหรับการสืบสวนผลกระทบทางอ้อมในงานวิจัยของคุณ ไม่ว่าคุณจะสร้าง mediation model in R สำหรับวิทยานิพนธ์ของคุณหรือสำรวจกลไกการคั่นกลางในข้อมูลจริง lavaan package มีความยืดหยุ่นและความแม่นยำที่คุณต้องการ
ต้องการความช่วยเหลือในการวิเคราะห์ที่เกี่ยวข้องหรือไม่? ดูคู่มือของเราเกี่ยวกับ การวิเคราะห์ตัวแปรคั่นกลางใน SPSS, การวิเคราะห์ตัวแปรกำกับใน R หรือเรียนรู้เกี่ยวกับ mediators vs moderators เพื่อเพิ่มความเข้าใจของคุณเกี่ยวกับเทคนิคทางสถิติขั้นสูง