Ești gata să-ți duci abilitățile de analiză a datelor la următorul nivel cu statistică descriptivă în R? Atunci să începem!
Statistica descriptivă reprezintă un set de tehnici care ne ajută să rezumăm și să descriem caracteristicile principale ale unui set de date. Ne ajută să obținem o înțelegere rapidă și simplă a datelor și este adesea primul pas în orice proces de analiză a datelor.
În această lecție, vom explora lumea statisticii descriptive în R. Vom începe prin pregătirea setului nostru de date despre vânzări și apoi vom calcula statistici descriptive importante precum media, mediana și modul, range-ul, deviația standard și varianța. Și odată ce avem aceste statistici, le vom folosi pentru a înțelege mai bine datele noastre și pentru a lua decizii informate.
Dar asta nu e tot! Vom analiza și câteva vizualizări de bază în R, precum histograme, box plots, scatter plots și trend lines. Aceste vizualizări ne vor ajuta să înțelegem mai bine distribuția și relațiile din datele noastre.
Deci, ești gata să înveți cum să realizezi statistică descriptivă în R? Atunci să începem!
Pasul 1: Pregătește-ți Setul de Date
Primul pas este să-ți pregătești setul de date și să-l stochezi în R ca vector. În acest exemplu, vom folosi 12 cifre de vânzări, fiecare reprezentând volumul vânzărilor pentru lunile ianuarie până decembrie:
sales <- c(16, 18, 13, 13, 14, 16, 21, 20, 19, 17, 15, 13)Pasul 2: Calculează Media
Prima noastră oprire este media, care ne oferă o idee despre cifra medie de vânzări pentru an. Pentru a calcula media în R, folosim funcția mean():
mean(sales)Rezultatul calculului mediei este 16.25, ceea ce ne spune că cifra medie de vânzări pentru an a fost de 16.25 unități.
Pasul 3: Calculează Mediana
În continuare, să calculăm mediana. Mediana este valoarea din mijloc într-un set de date și poate fi un indicator mai bun al cifrei tipice de vânzări dacă datele sunt asimetrice. Pentru a calcula mediana în R, folosim funcția median():
median(sales)Rezultatul calculului medianei este 16, ceea ce ne spune că valoarea din mijloc a cifrelor de vânzări pentru an a fost de 16 unități.
Pasul 4: Calculează Modul
O altă statistică descriptivă importantă este modul, care reprezintă valoarea care apare cel mai des într-un set de date. Pentru a calcula modul în R, folosim funcțiile table() și which.max():
mode <- table(sales)
mode[which.max(mode)]Rezultatul calculului modului este 13, ceea ce ne spune că cifra cea mai frecventă de vânzări pentru an a fost de 13 unități.
Pasul 5: Calculează Range-ul
Putem calcula și range-ul, care ne oferă o idee despre cât de răspândite sunt datele. Pentru a calcula range-ul în R, folosim funcția range():
range(sales)Rezultatul calculului range-ului este 8, ceea ce ne spune că cifrele de vânzări au variat cu 8 unități între cifra minimă (13) și maximă (21) de vânzări pentru an.
Pasul 6: Calculează Deviația Standard
În continuare, să calculăm deviația standard. Deviația standard este o măsură a cât de răspândite sunt datele și ne oferă o idee despre cât variază cifrele de vânzări față de medie.
Pentru a calcula deviația standard în R, folosim funcția sd():
sd(sales)Rezultatul calculului deviației standard este 2.8, ceea ce ne spune că cifrele de vânzări au variat de la medie cu o medie de 2.8 unități.
Pasul 7: Calculează Varianța
În final, vom calcula varianța. Varianța este similară cu deviația standard, dar în loc să ne ofere deviația medie de la medie în unități, ne oferă deviația medie de la medie la pătrat. Pentru a calcula varianța în R, folosim funcția var():
var(sales)Rezultatul calculului varianței este 7.84, ceea ce ne spune că cifrele de vânzări au variat de la medie cu o medie de 7.84 unități la pătrat.
Pasul 8: Creează o Histogramă
Acum că am calculat câteva statistici descriptive de bază, să analizăm datele vizual prin crearea unei histograme. Pentru a crea o histogramă în R, folosim funcția hist():
hist(sales)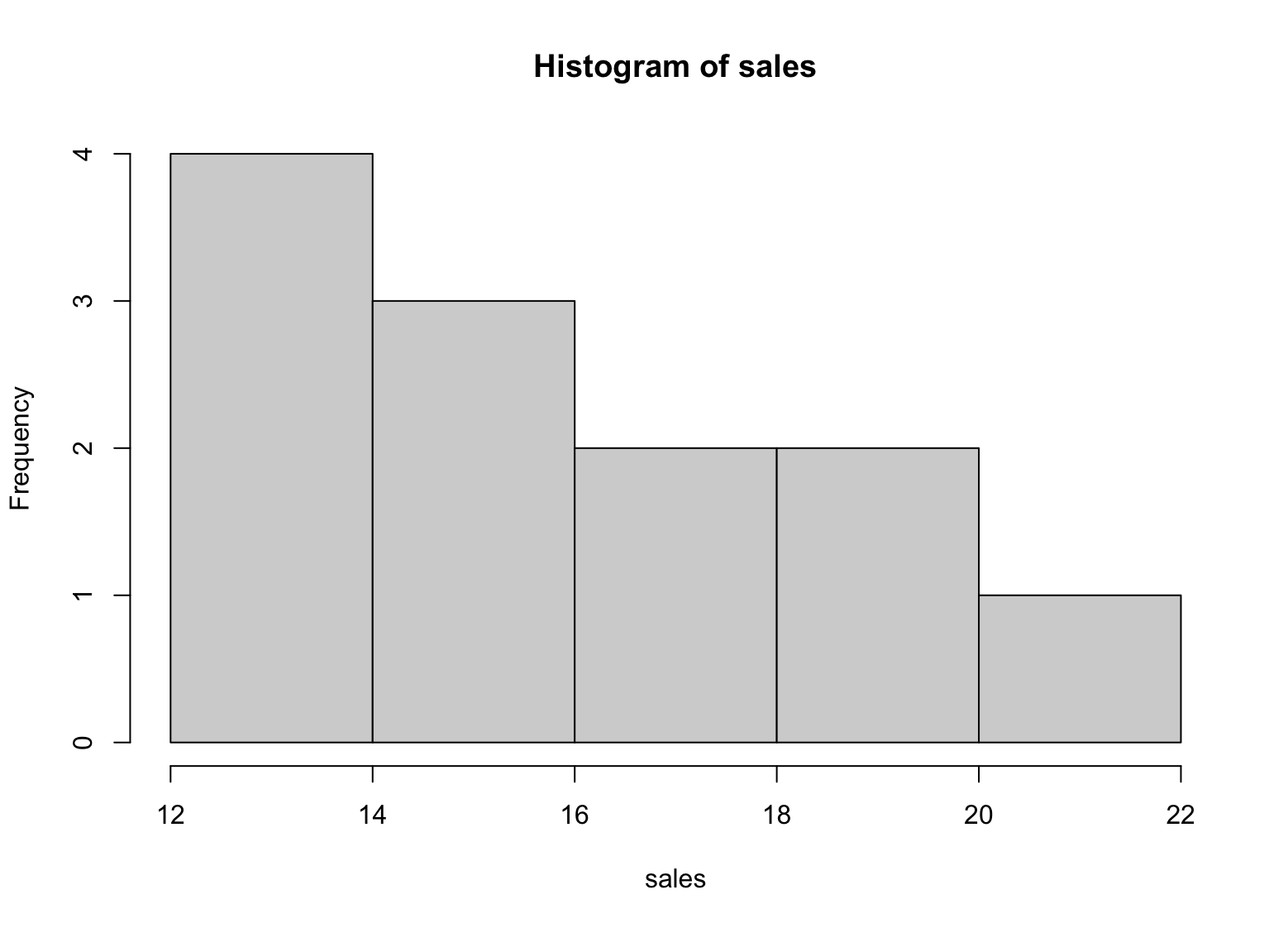
Exemplu de histogramă pentru statistică descriptivă în R
Histograma ne oferă o reprezentare vizuală a distribuției cifrelor de vânzări pentru an. Ne arată că majoritatea cifrelor de vânzări se situează între 13 și 18, și există mai puține cifre de vânzări la capetele superioare și inferioare ale range-ului.
Pasul 9: Adaugă un Scatter Plot
Pentru a crea un scatter plot în R, poți folosi funcția plot(). Sintaxa de bază este următoarea:
plot(x, y, main = "Scatter Plot", xlab = "X Variable", ylab = "Y Variable", pch = 16)Aici, x și y sunt variabilele pe care vrei să le reprezinți. Argumentul main este titlul graficului, xlab și ylab sunt etichetele pentru axa x și axa y, respectiv, iar pch este simbolul de reprezentare folosit.
Deoarece avem doar o singură variabilă în datele noastre de vânzări, o putem reprezenta grafic în funcție de secvența numerelor de vânzări pentru a crea un scatter plot:
x <- 1:12
plot(x, sales, main = "Scatter Plot of Sales", xlab = "Month", ylab = "Sales", pch = 16)Aceasta va crea un scatter plot al datelor de vânzări, cu lunile pe axa x și cifrele de vânzări pe axa y. Argumentul pch setează simbolul de reprezentare la un cerc solid (16).
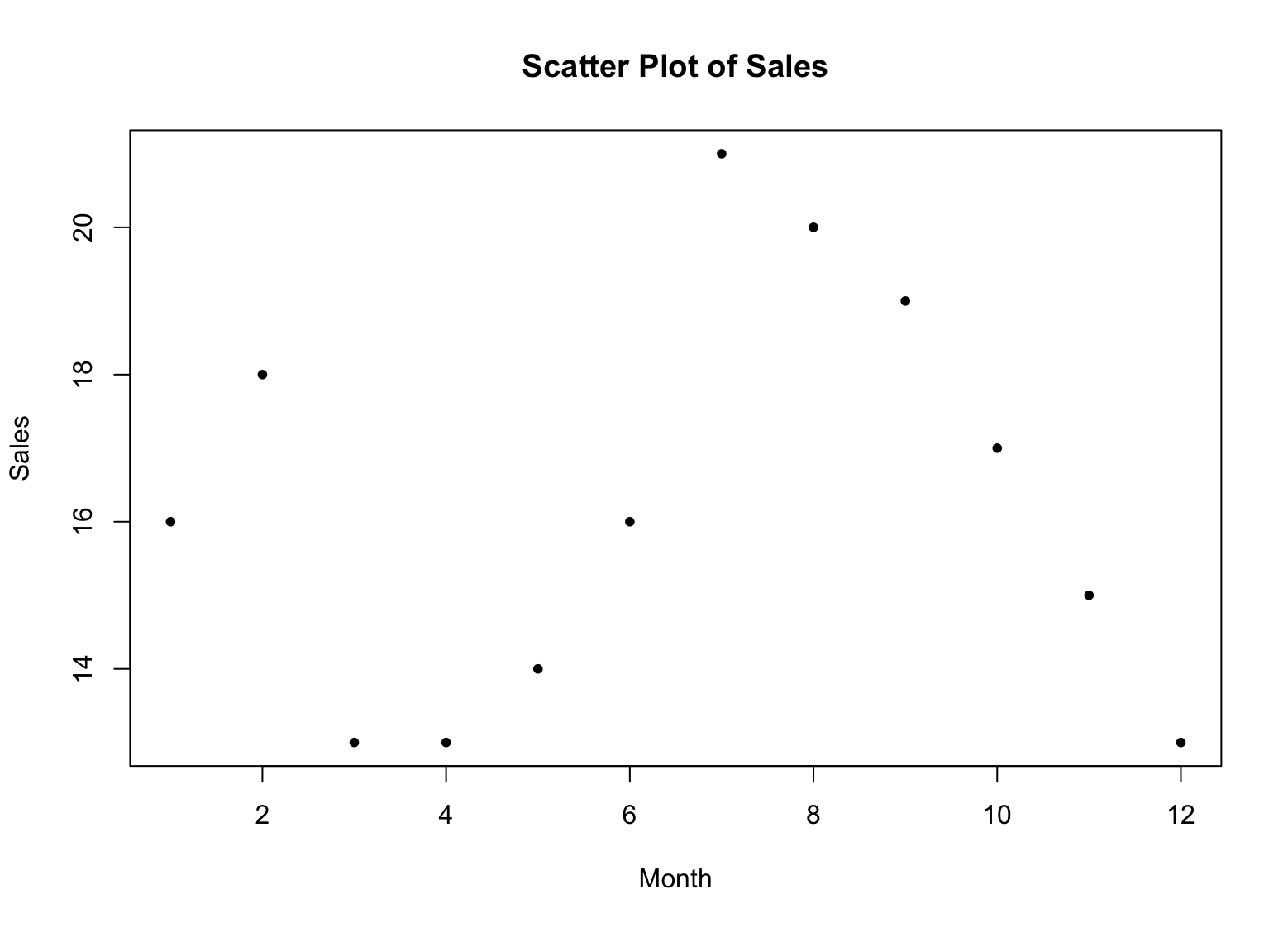
Exemplu de scatter plot în R
Hmm... am obținut o serie de puncte, dar cred că este mai ușor de vizualizat dacă avem o linie care conectează aceste puncte. Iată sintaxa pentru a conecta punctele cu o linie albastră:
lines(x, sales, type = "l", col = "blue")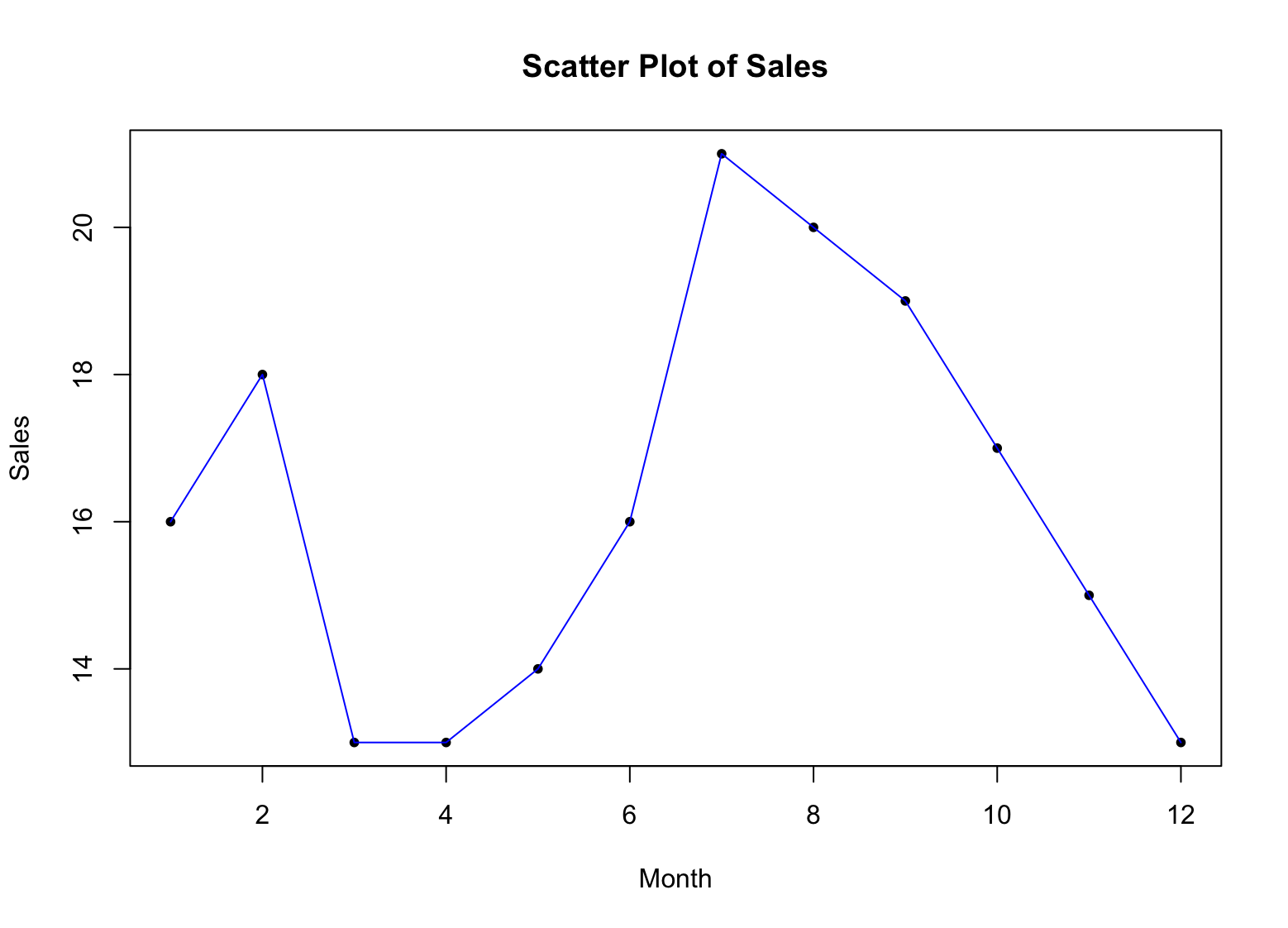
Exemplu de scatter plot cu linii în R
Bine, și acum ce? Cum interpretăm acest grafic în contextul datelor noastre de vânzări?
-
Fiecare punct de pe scatter plot reprezintă un singur punct de date, cu axa x reprezentând lunile și axa y reprezentând cifrele de vânzări.
-
Privind distribuția punctelor pe scatter plot, poți înțelege cum sunt distribuite cifrele de vânzări pe luni. Dacă punctele sunt strâns grupate, sugerează că cifrele de vânzări sunt similare pe luni. Dacă punctele sunt mai răspândite, sugerează că cifrele de vânzări sunt mai variabile pe luni.
-
Căutând modele în distribuția punctelor, poți identifica orice tendințe sau modele în date. De exemplu, dacă punctele formează o linie dreaptă, sugerează că există o relație liniară între luni și cifrele de vânzări. Dacă punctele formează o linie curbă, sugerează că există o relație neliniară între luni și cifrele de vânzări.
-
Valorile extreme (outliers) sunt reprezentate ca puncte individuale care sunt semnificativ diferite de restul datelor. Identificând outliers, poți vedea dacă există luni cu cifre de vânzări semnificativ mai mari sau mai mici, care pot necesita investigații suplimentare.
Să facem scatter plot-ul nostru mai semnificativ și să adăugăm o linie de tendință folosind funcția abline():
fit <- lm(sales ~ x)
abline(fit, col = "red")Aceasta va adăuga o linie de regresie la grafic, arătând tendința generală în datele de vânzări. Argumentul col setează culoarea liniei la roșu. Desigur, poți alege orice altă culoare care îți place.
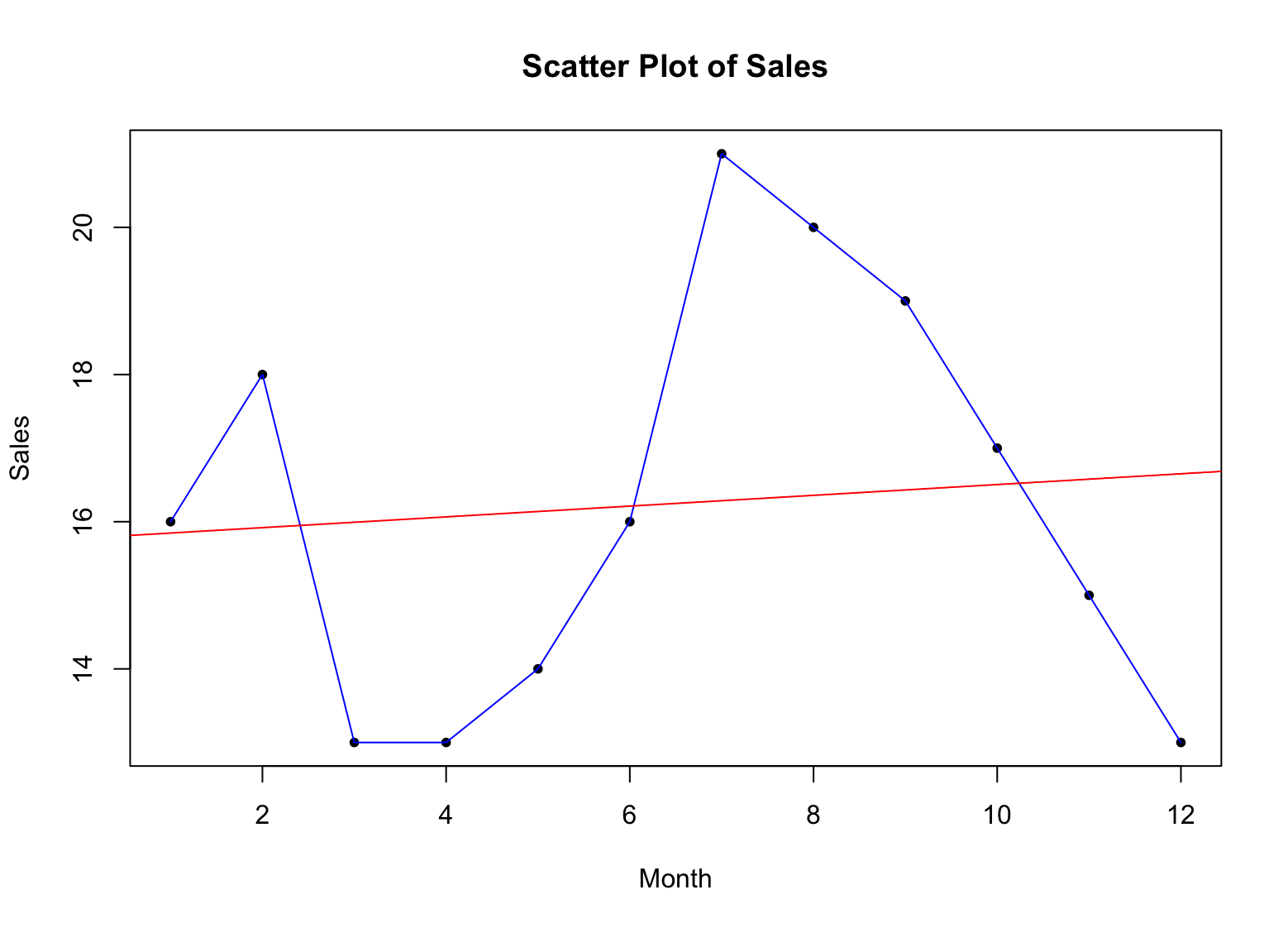
Exemplu de scatter plot cu linie de tendință pentru statistică descriptivă în R
Pasul 10: Creează un Box and Whisker Plot
În R, poți crea un box and whisker plot, cunoscut și ca boxplot, folosind funcția boxplot(). Sintaxa de bază este următoarea:
boxplot(x, main = "Box and Whisker Plot", xlab = "Group", ylab = "Value", col = "blue")Aici, x este variabila pe care vrei să o reprezinți grafic, main este titlul graficului, xlab și ylab sunt etichetele pentru axa x și axa y, respectiv, iar col este culoarea boxplot-ului.
De exemplu, pentru a crea un box and whisker plot al datelor de vânzări, poți folosi următorul cod:
boxplot(sales, main = "Box and Whisker Plot of Sales", xlab = "Month", ylab = "Sales", col = "blue")Aceasta va crea un box and whisker plot al datelor de vânzări, cu lunile pe axa x și cifrele de vânzări pe axa y. Argumentul col setează culoarea boxplot-ului la albastru.
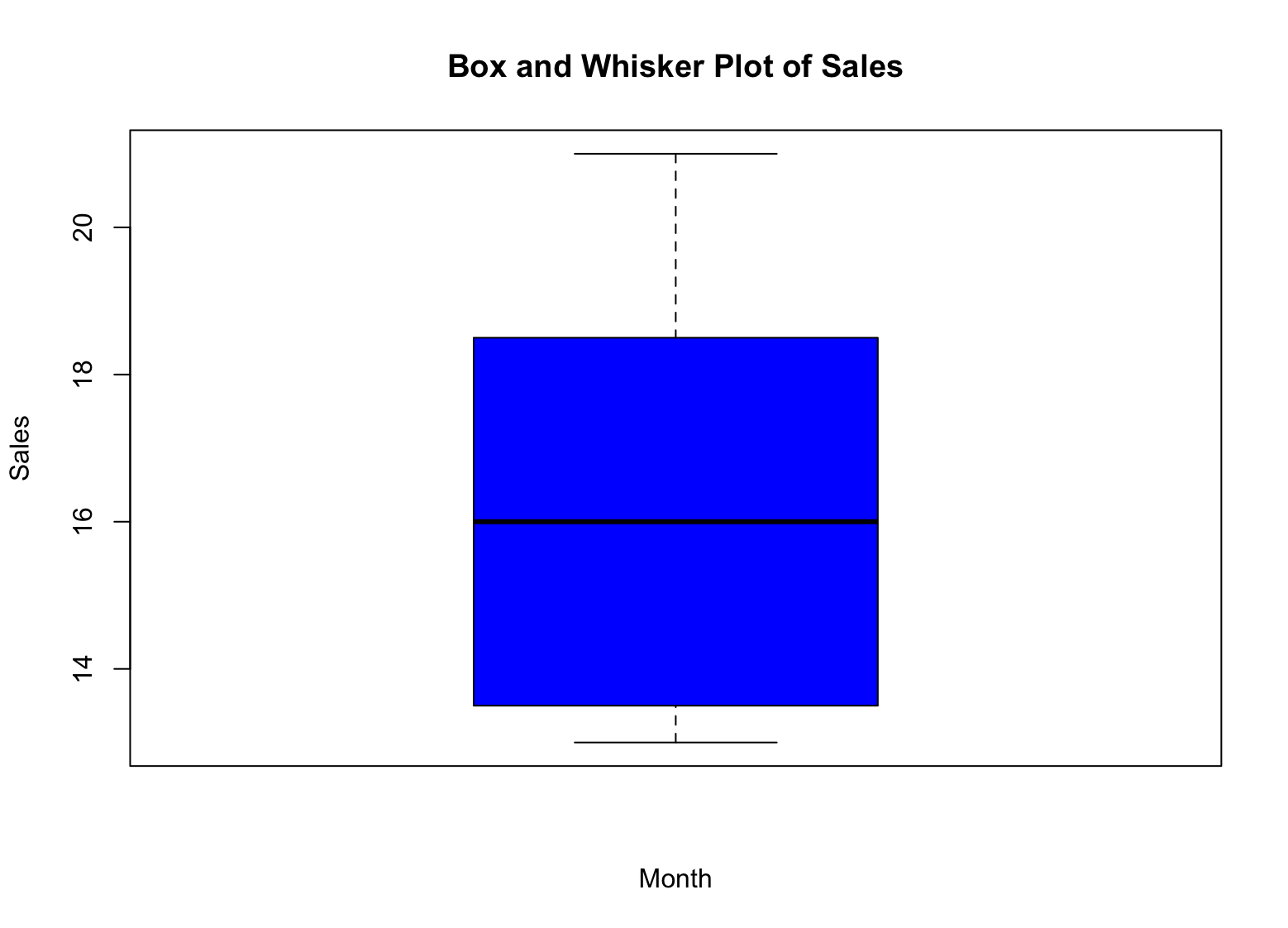
Exemplu de box plot pentru statistică descriptivă în R
Deci, cum interpretăm box and whisker plot-ul pentru datele noastre de vânzări? Iată cum:
-
Caseta (box) reprezintă intervalul intercuartilic (IQR), care este intervalul dintre primul și al treilea cuartil (percentilele 25 și 75) ale datelor. Înălțimea casetei reprezintă IQR-ul.
-
Mediana este reprezentată printr-o linie în interiorul casetei. Este valoarea care separă jumătățile superioare și inferioare ale datelor.
-
"Mustățile" (whiskers) reprezintă valorile minime și maxime ale datelor, excluzând orice valori extreme. Valorile extreme sunt reprezentate ca puncte individuale în afara mustăților.
-
Valorile extreme (outliers) sunt reprezentate ca puncte individuale în afara mustăților. Ele reprezintă valori care sunt semnificativ diferite de restul datelor.
Analizând box and whisker plot-ul datelor de vânzări, poți vedea rapid distribuția cifrelor de vânzări pentru an. Poți vedea unde se află mediana, precum și intervalul de valori (IQR) și orice potențiale valori extreme. Aceste informații te pot ajuta să iei decizii informate despre datele tale și să identifici orice zone care pot necesita investigații suplimentare.
Întrebări Frecvente
Concluzie
Și asta e tot! Sperăm că ți-a plăcut această călătorie în lumea statisticii descriptive în R. Am acoperit destul de mult teren, de la calcularea unor statistici descriptive importante precum media, mediana, modul, range-ul, deviația standard și varianța, până la reprezentarea vizuală a datelor folosind box plot, scatter plot și linie de tendință.
Sperăm că ai găsit acest articol util și că acum ai o înțelegere mai bună a modului de a realiza statistică descriptivă în R. Ține minte, statistica descriptivă este doar primul pas în orice proces de analiză a datelor, așa că nu ezita să explorezi mai departe și să te scufunzi mai adânc în lumea analizei datelor. Și iată o sugestie bună: exemplu simplu de regresie liniară în R.
Deci continuă, explorează-ți datele și nu înceta niciodată să înveți! Și ca întotdeauna, analiză fericită a datelor!